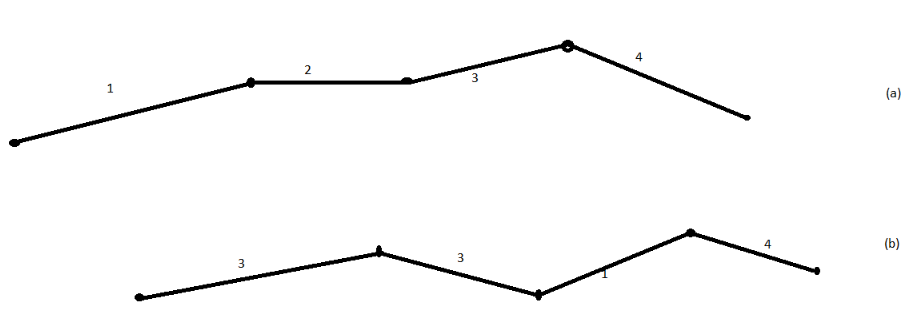
ColB
2
a
3
a
3
a
2
b
1
b
4
b
3
c
4
c
I have this above input where I would like to delete the whole group (a, b, c) from ColB, if there is a '2' in ColA in the specified group.
For example, if there is a 2 in ColA, the whole group 'a' is removed from ColB (and not just the specified row).