Hello, I am trying to create a workspace for doing a batch identification of information contained in tables within some pdf files, the thing is that the pdf also contains some other information as text, so I am a little bit confused on how to achieve that, and also if it will work with different tables, because the dataset I have was made by multiple authors so they are different tables on each pdf. I am wondering if it would be better to use a external application or a PythonCaller to achieve that, but before trying that out I would like to confirm first. I am attaching a sample pdf of my dataset so you can see the table that is in it. Thank you!

Solved
How would I read a table from multiple pdf if they are different and they are not tagged?
 +2
+2Best answer by geomancer
Thanks for the sample @hkingsbury I can follow the process, but in terms of looking to set up an 'attribute' table based on an incoming table, what might be the things to keep in mind? Considering that I have filtered the text that is supposed to be the content of the table as it shows me.
Hi @juandiegoboh , as I had a slow day at the office today, I decided to take on this challenge. And with some success!
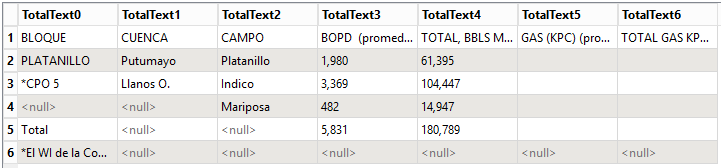 I couldn't have done this without the basics provided by @hkingsbury .
I couldn't have done this without the basics provided by @hkingsbury .
There were several hurdles to be taken along the way:
- Recreate the cells of the table;
- Create a single text from the multiple texts in one cell;
- Think of a way to handle the merged cells;
- Think of a way to create the attributes to write the texts to.
These challenges lead to many wrong turns and dead ends along the way.
For the merged cells from the table the text is written into the attribute representing the topmost and leftmost cell only; the other attributes are left empty.
Please dive into the attached workspace to find out exactly how it all works. I am not sure whether this solution is optimal, or whether it is usable for other PDF files, but I had a lot of fun today.
Now it's high time I get on with my regular work!
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.





Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.