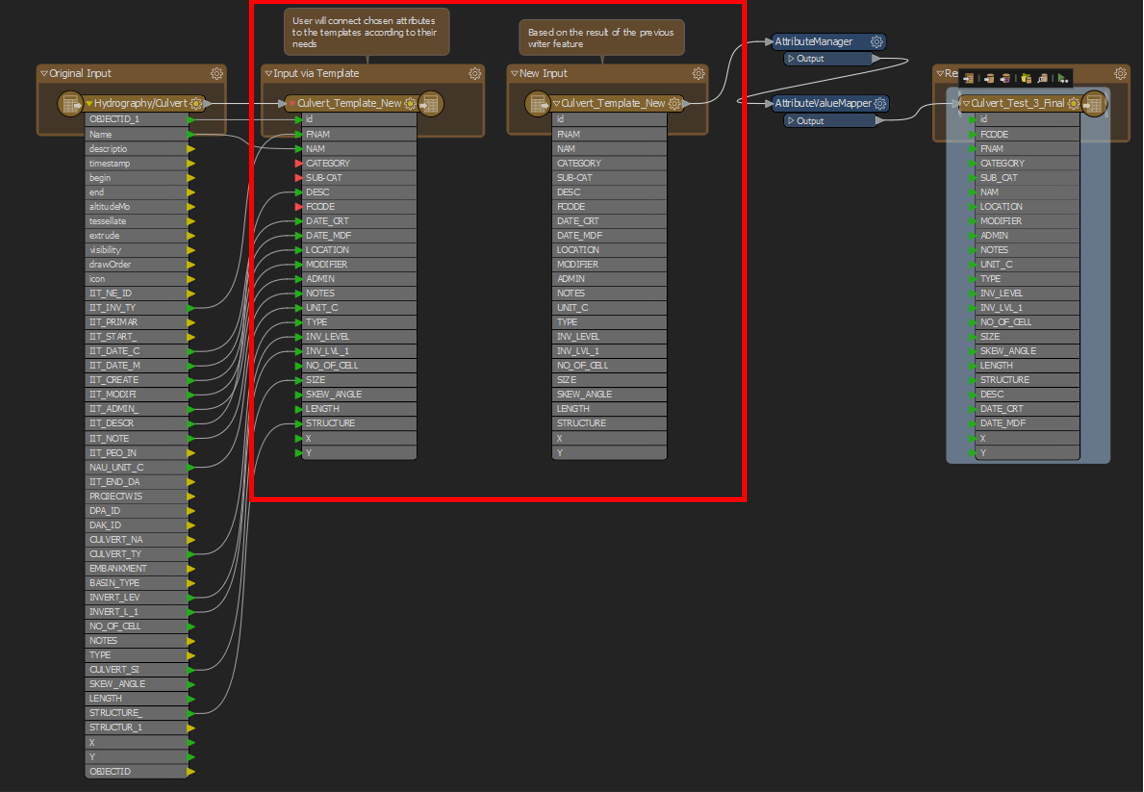
 The first writer feature was done by connecting the list of wanted attributes to the attributes template I have done. So I run it and wanted to proceed to a new translation which involved transformers. Is there any possibility I can just connect the writer to feature so I don't have to run it twice?
The first writer feature was done by connecting the list of wanted attributes to the attributes template I have done. So I run it and wanted to proceed to a new translation which involved transformers. Is there any possibility I can just connect the writer to feature so I don't have to run it twice?

Question
Hi I am fairly new to FME. I wanted to ask if there is any other way for me to run the workbench only once.
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.





Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.