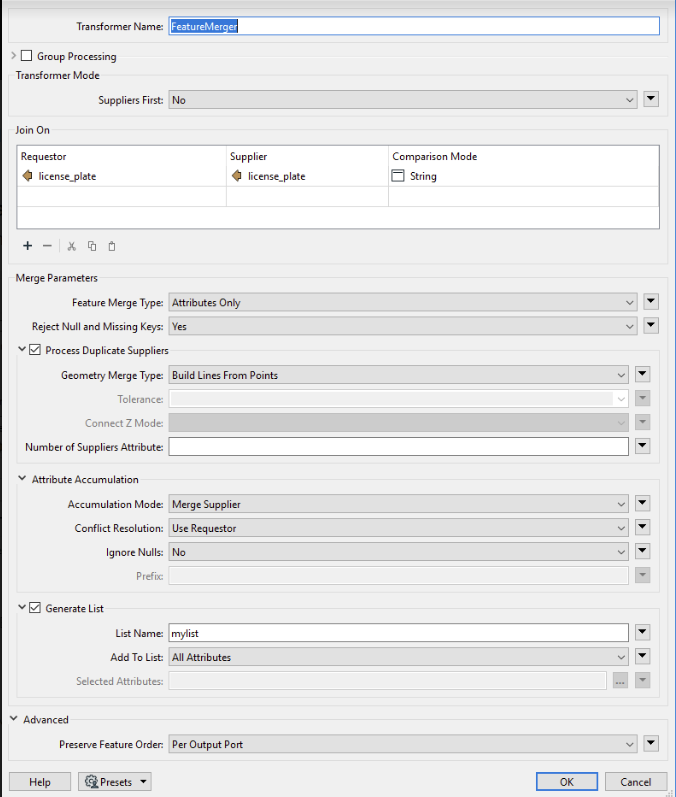
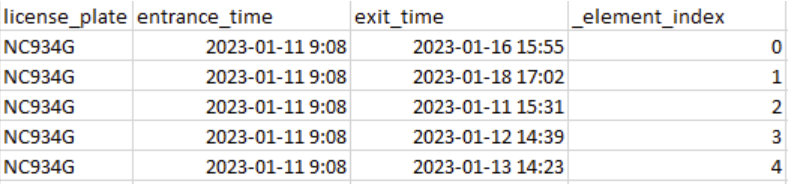
Hi I'm currently trying to combine 2 datasets based on a shared set value where table 1 attribute 1 ex. = 500, and table 2 Attribute1 also = 500, and there would be duplicate 500 values in both datasets
so to do an effective Join I'm attempting to also join on *closest mileage value, the mileage is not exactly the same between the two tables so it would need to be within rage or closet to sort of function where first the join would be attribute 1 being the same between both tables and then joining table 2 to table 1 where the mileage from table 2 is cloest to table 1 mileage.