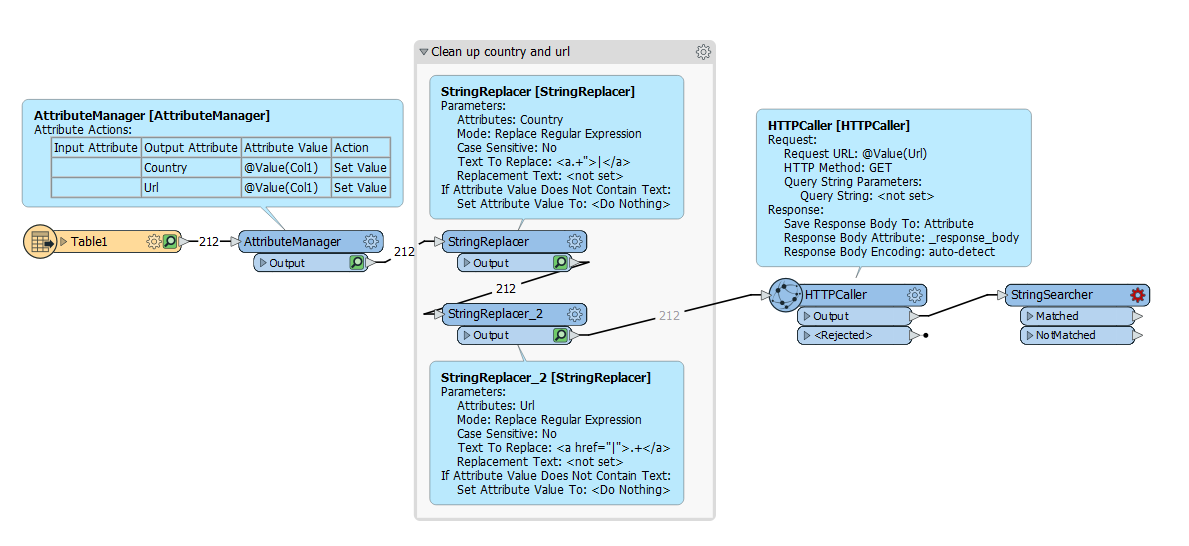
Hello FME community,
I have never used FME to scrape web pages but I am looking to do so but I don't know where to start. The web source I am looking at provides country-specific COVID information.
What I would like to do is scrape each of the country links provided on the site and pull data into a tabular format. Eventually, I would like to join this data to global admin boundaries.
Would this be possible using FME? Does anyone know where I could start? Thanks, FME Family!