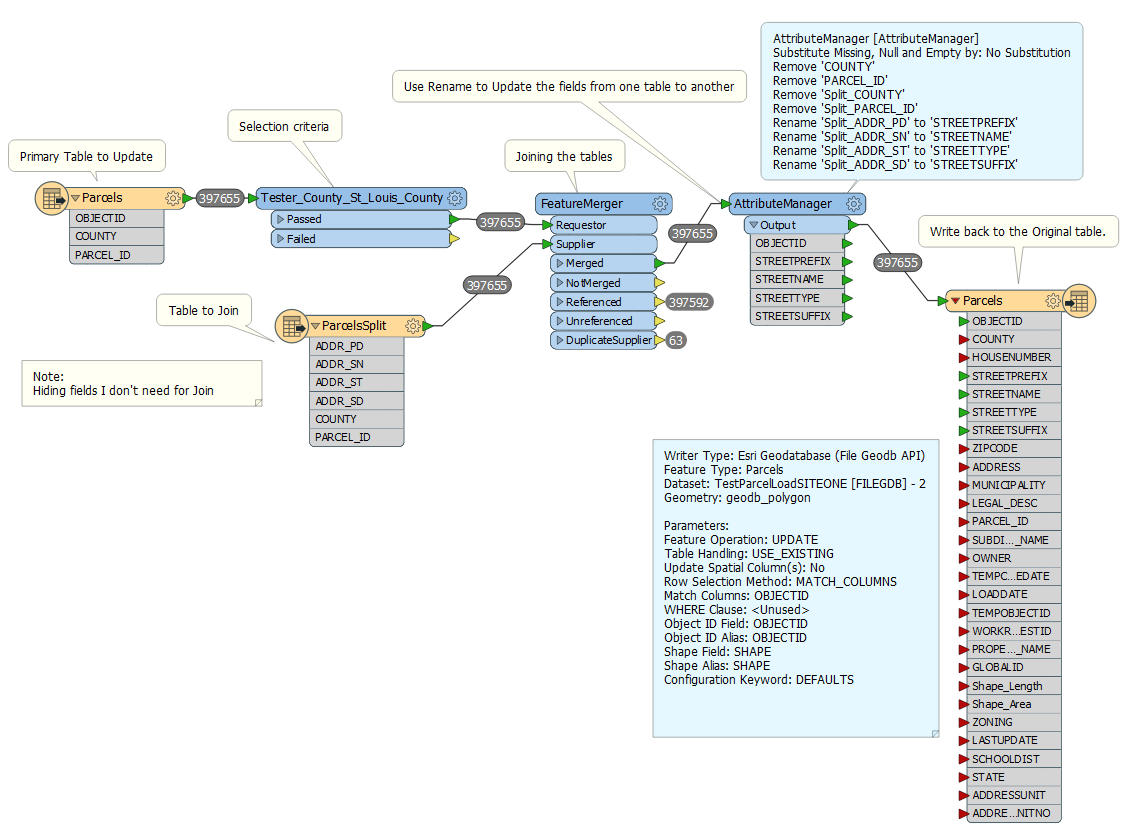
I want to mimic the process of joining another table to a featureclass and calculate an existing field based on the join table for selected records. Since I have several fields I want to update, I thought FME would be a good option.
Does the process below look like the correct approach?
Do indexes in the database help? Or is FME handling this in memory?