



Hi, I'm inefficient with CSS selector statements - having no HTML authoring background. I want the CSV download links at this site and only the csv download links:
https://data.sandiego.gov/datasets/parking-citations/
I can get all 'a' tags and the href references no problem but have to test the result ends with '.csv'. Can anyone give me the right selector syntax for the element I'm after? Thanks all.
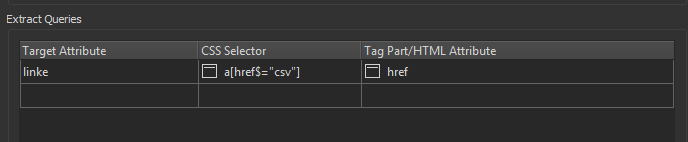



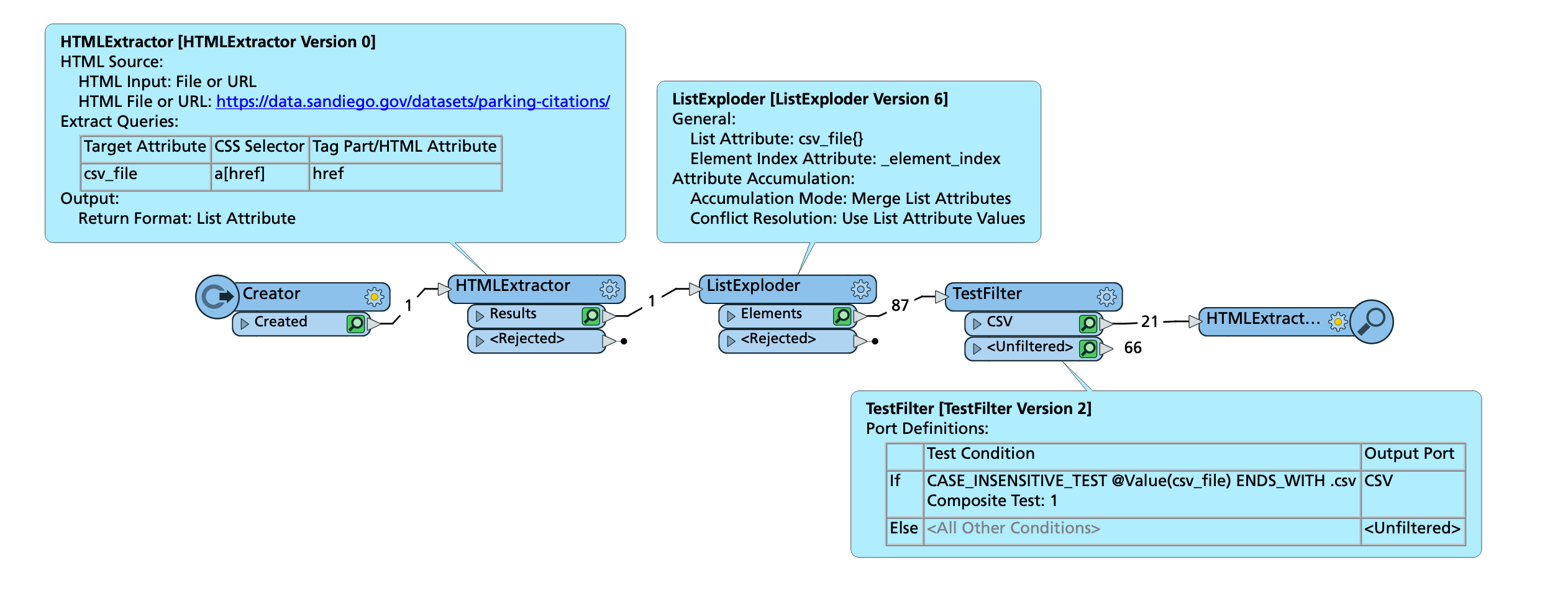 In addition to that, the filenames are actually predictable, you don't really have to go through the HTMLExtractor at all...
In addition to that, the filenames are actually predictable, you don't really have to go through the HTMLExtractor at all...
