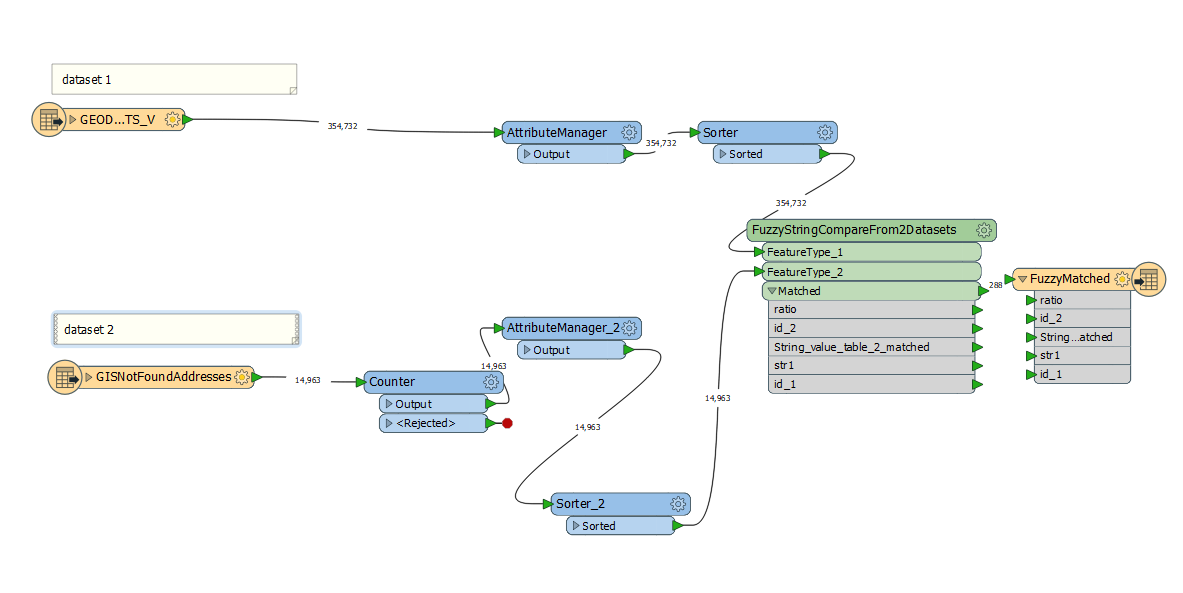
I'm trying to compare two datasets by looking at the address attribute string used in both datasets and find the fuzzy matching ratios. The read process was fast and read the 350,000 records in dataset 1 and the 14,000 records in dataset 2 in less than a minute. I then sort both lists separately and then use the FuzzyStringCompareFrom2Datasets transformer. I have been running this workspace all day (about 5 hours so far) and it has only output 288 records. Is there a way to speed this up?