Hi,
In a workbench, I created a Custom Transformer to loop batch of features.
It is a workaround to prevent machine reboot on large feature datasets processing. At least, writing-along features in the Output to .csv. file help to recover features processed in PythonCaller and it is easier to resume for the remaining features…
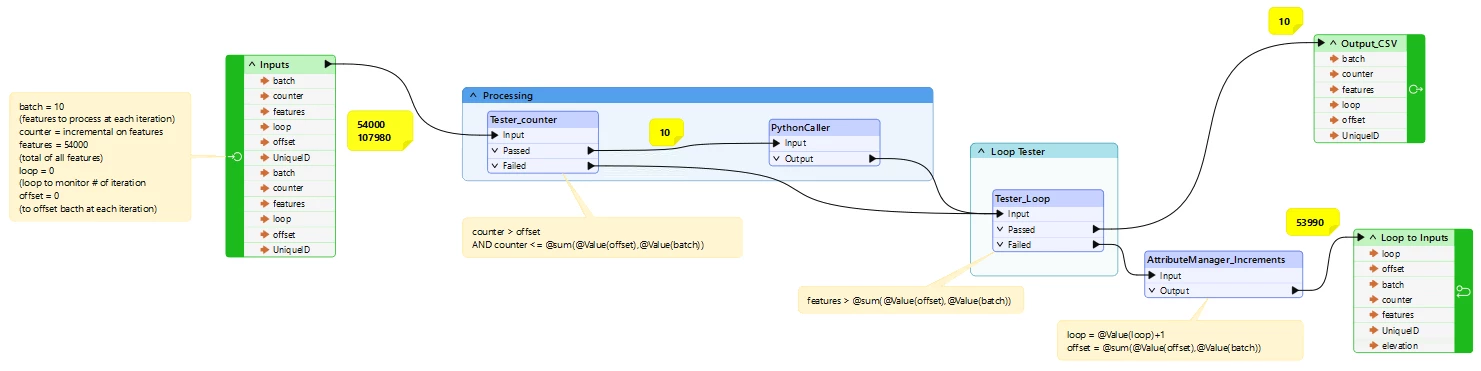
Here is the workbench, with Inputs:
batch = 10
counter = 54000 (total of features)
loop = 0 (to keep track of iteration)
offset = 0
The Tester_counter transformer filter out batches 10 features at each iteration, sent to PythonCaller. At the end of processing the Tester_Loop tests if there is remaining features to process. Anything processed is sent to the Output and written in a .csv Writer transformer in the ‘Main’ workbench, whereas ‘failed’ remaining features from Tester_counter have their attributes incremented for variables loop and offset for the next iteration.
However, when running the workbench, the output .csv file is created but kept empty. Also, each iteration resent features incrementally from the inputs (as shown in yellow). As a result, it does not work!
Is there anything obvious to fix? Or is there anything wrong in the looping logic?
Thanks