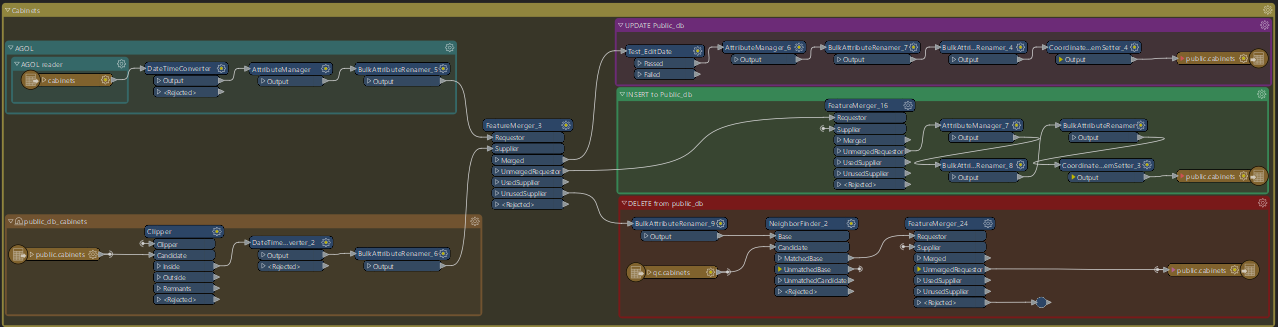
I am currently working with about 60 towns (folders) on AGOL which all contain 10+ feature layers. The data is read from all these layer (reader per layer), compared with data in my db, then the data is updated/inserted/deleted in our db.
After this, let's say some work is done on the db data . I then have another workspace which is writing the updates back up to AGOL for the same town.
I currently have 2 workspaces per town which take care of all the reading/writing/processing for all the layers. This has resulted in 120 workbenches which, when an update has to be made to the way data is processed, I have to go back and update all of those workspaces. Also more towns are being added every week so the number of workbenches is increasing.
The screenshot below is taken from one layer where data is read from both AGOL and the db, compared and then written out. I have a section like this for every layer where the processing is largely the same, with small differences depending on if it's a point, line or polygon.
Would anybody have any suggestions on streamlining this process so that I don't have to go back and change hundreds of workspaces when an update goes out? Any help would be greatly appreciated.