

I'm attempting to extract a link from html that looks something like this: <a class="email-link" href="https://app.myapp.com/results/a7696ced77454dd39d8241e79f981b3d">here</a>. using the xquery extractor. the x-query //a/@href seems to work in the online testers but not in FME. Any ideas?
Best answer by debbiatsafe
View original



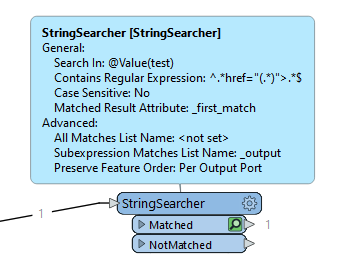



![Use the XQuery expression //a/data(@href) in the XMLXQueryExtractor or CSS selector a[href] in HTMLExtractor](https://uploads-us-west-2.insided.com/safesoftware-en/attachment/0684Q00000Li4iLQAR.png)