



I have many files in this ascii format. The RRC has MAGNETIC TAPE USER GUIDE with field descriptions that contain beginning and ending positions. I have attempted to use the schema mapper with csv file that describes this but have yet to figure out how to make that work.
please help,
Files are located here.
 The file looks like this...
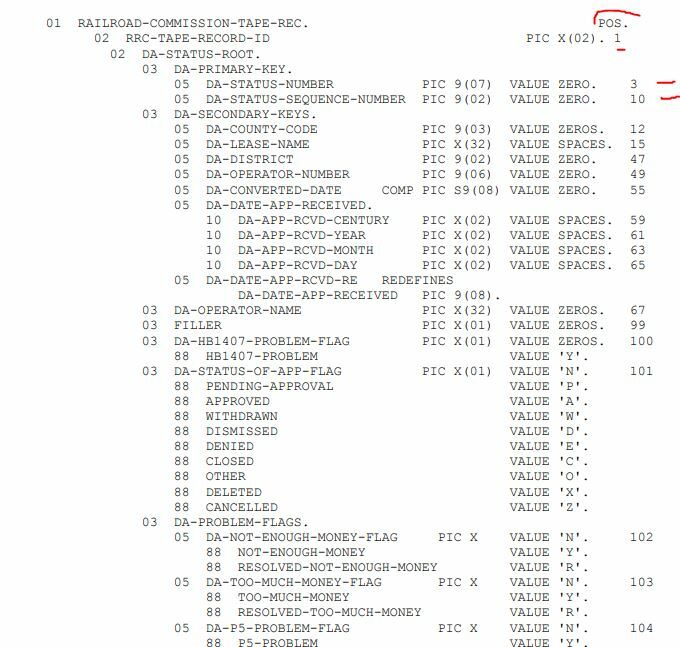
The file looks like this...
 The format description is like total bytes per record 308 bytes.
The format description is like total bytes per record 308 bytes.
MASTER FILE TAPE RECORD
SEGMENT KEY NAME DESCRIPTION
01 DAROOT DA ROOT SEGMENT
02 DAPERMIT DA PERMIT MASTER SEGMENT
03 DAFIELD DA FIELD SEGMENT
04 DAFLDSPC DA FIELD SPECIFIC DATA SEGMENT
05 DAFLDBHL DA FIELD BOTTOM-HOLE LOCATION SEGMENT
06 DACANRES DA CANNED RESTRICTIONS
07 DACANFLD DA CANNED RESTRICTION FIELDS
08 DAFRERES DA FREE-FORM RESTRICTIONS
09 DAFREFLD DA FREE-FORM RESTRICTION FIELDS
10 DAPMTBHL DA BOTTOM-HOLE LOCATION SEGMENT
11 DAALTADD DA ALTERNATE ADDRESS SEGMENT
12 DAREMARK DA PERMIT REMARKS
13 DACHECK DA CHECK REGISTER SEGMENT
14 DAW999A1 DA GIS SURFACE LOCATION COORDINATES
15 DAW999B1 DA GIS BOTTOM HOLE LOCATION COORDINATES
attrib1 position1
attrib2 position3
attrib3 postion10
 so on and so forth.
so on and so forth.
how do i get a schema mapper to recognize this?
Or is it something other than a schema mapper that i need to use?
