I have recently installed FME Desktop 2022.0 (Database edition – Build 22337 – WIN64) and want to migrate old workspaces to this latest version.
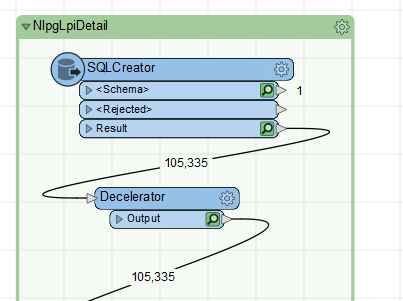
I have a workspace that was written and runs in FME Desktop 2019.0 (Database edition). It reads in about 120,000 records via SQL Creator (non-spatial Microsoft SQL data format), does some transformations, and writes to a CSV file. It works perfectly in FME Desktop 2019.0.
However, when I open and run the same workspace in FME Desktop 2022.0 it is not working correctly.
I have tried this on Windows 10 Enterprise and Windows Server 2012 R2.
I have tried with Feature Cache on and off.
I have tried running as a batch process.
I have tried running the workspace in 2022.0 unchanged (as a 2019.0 workspace).
I have tried running the workspace in 2022.0 unchanged (as a 2022.0 workspace).
I have tried running in 2022.0 with transformers upgraded to the latest 2022.0 versions.
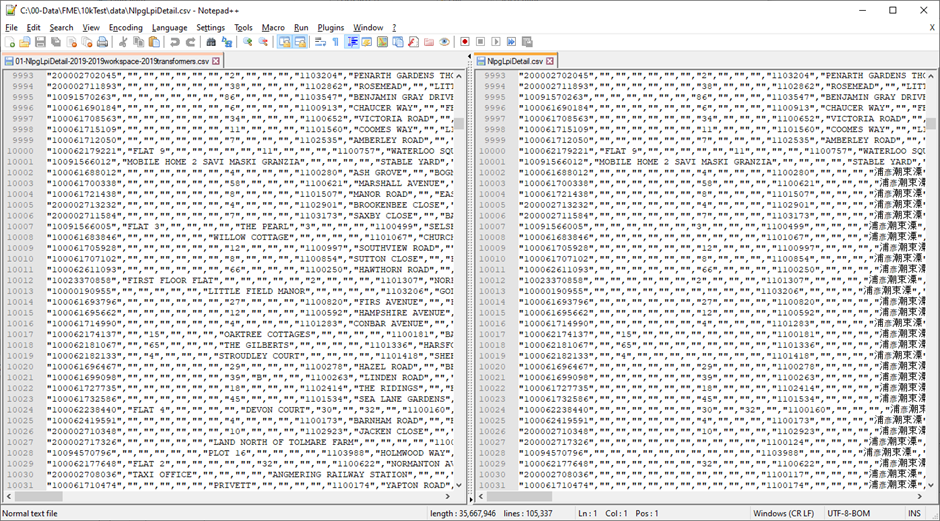
In all cases after every 10,000 records, several records are corrupted on the output. Some column values are missing or else filled with unprintable characters. Some column values are from other records. The actual corruption differs depending on whether the workspace is run with feature caching, without feature caching, or batch run from command line.
Using Feature Cache, inspecting the records output from the SQL Creator, all records are present and clean. However, viewing the records after an AttributeSplitter transformer, records are corrupt.
I have also tried this on other workspaces and the same problem exists. I have tried using the standard MS SQL Reader and have the same problem.
I wonder if anyone else has experienced this and if so, what can be done to resolve the issue.
I attach the workspace and log file. I am unable to upload data because it is in an MS SQL database and is confidential.
In the screen grab below, the 2019 processed data is on the left and the 2022 processed data is on the right.
Best answer by JennaKAtSafe
View original