
I have created a workspace which has a prompt for user parameters, as I want the user to be able to run the workflow on different sets of data.
The workspace reads in a set of CSVs which have identical schema, performs some transformations and then writes the data out into a single CSV. The process works for what I want it to do.
The problem is when the prompt comes up to run and I choose a different set of CSVs, these CSVs have the same schema as each other but not the same schema as the previous set of data. The attributes that are used in the transformations are the same but other attributes are different and this data does not get read in. I want the reader to read in the new schema each time, but it always retains the schema from the first set of data I used to set up the reader.
How can I fix this?

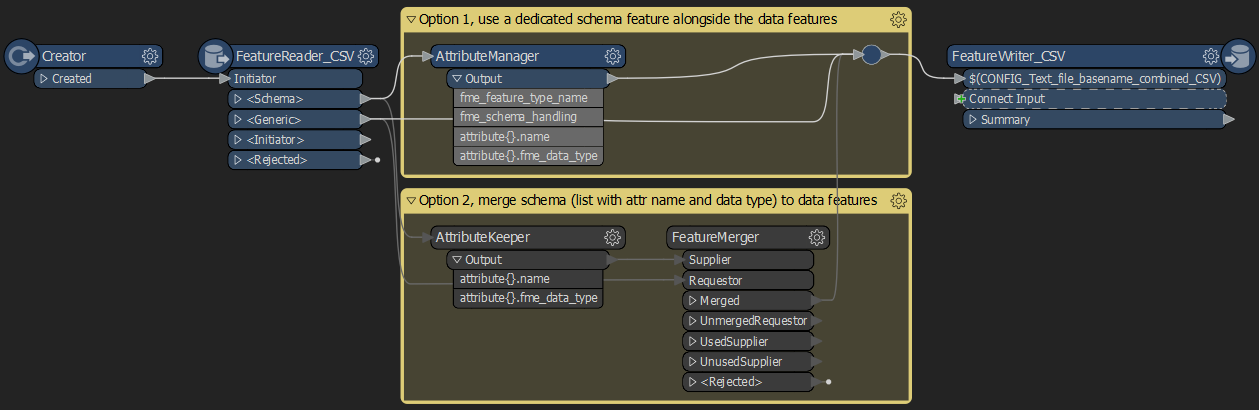 But if you choose to use regular Readers and Writers, your workspace could become even more compact by cloning the schema of the Reader to the Writer. Then it could look as simple as this;
But if you choose to use regular Readers and Writers, your workspace could become even more compact by cloning the schema of the Reader to the Writer. Then it could look as simple as this; Hope it can help.
Hope it can help.  Not sure why this is happening
Not sure why this is happening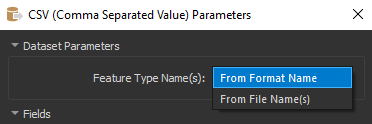 Similarly, what kind of settings did you use for the writer feature types?
Similarly, what kind of settings did you use for the writer feature types? 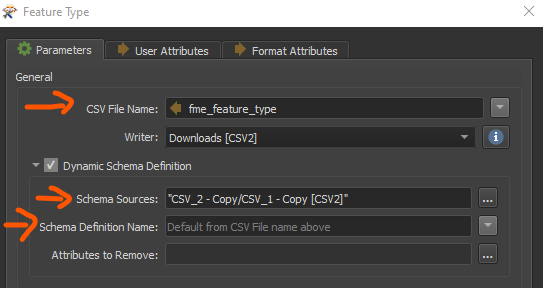 Did you maybe change the CSV File name parameter to a new (user parameter) value?
Did you maybe change the CSV File name parameter to a new (user parameter) value?