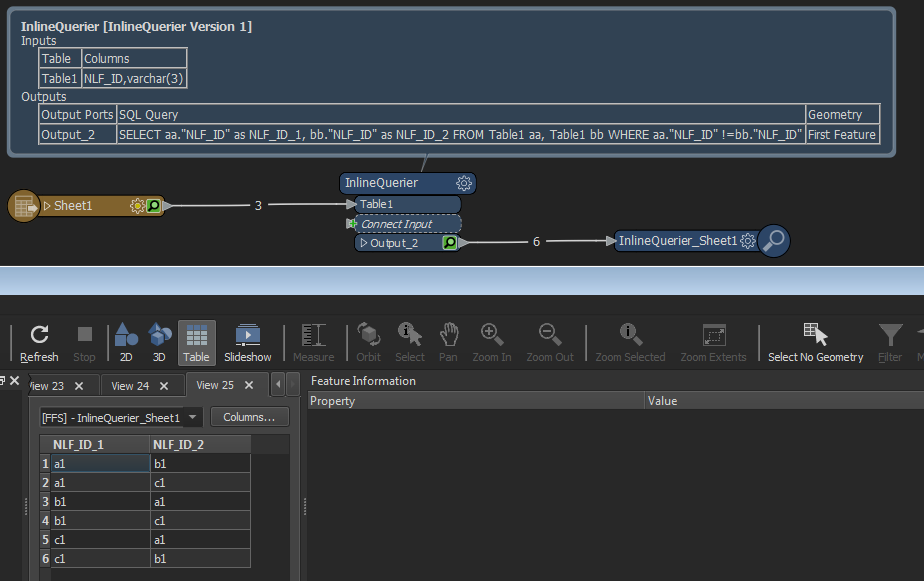
I was able to implement this in the python caller which produces the result but when I substitute the hard coded data for "myList" it does not work for me.
import itertools
myList = [
['a1', 'b1', 'c1'],
['a1', 'b1', 'c1']
]
for x in itertools.product(*myList):
results = list(itertools.product(myList))
print (x)
How do I pass the output in my list out? How do I substitute myList with the data from my DB.
CODE in Python Caller which lists results in the translation log
import fme
import fmeobjects
import itertools
# Template Function interface:
# When using this function, make sure its name is set as the value of
# the 'Class or Function to Process Features' transformer parameter
def processFeature(feature):
pass
# Template Class Interface:
# When using this class, make sure its name is set as the value of
# the 'Class or Function to Process Features' transformer parameter
class FeatureProcessor(object):
def __init__(self):
pass
def input(self,feature):
somelists = [['a1', 'b1', 'c1'],['a1', 'b1', 'c1']]
for elements in itertools.product(*somelists):
print (elements)
self.pyoutput(feature)
def close(self):
pass
Best answer by ebygomm
View original