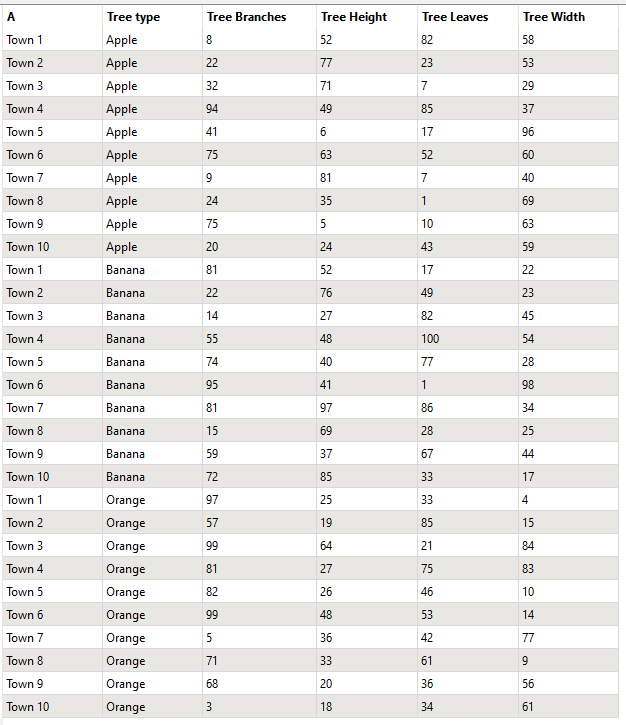
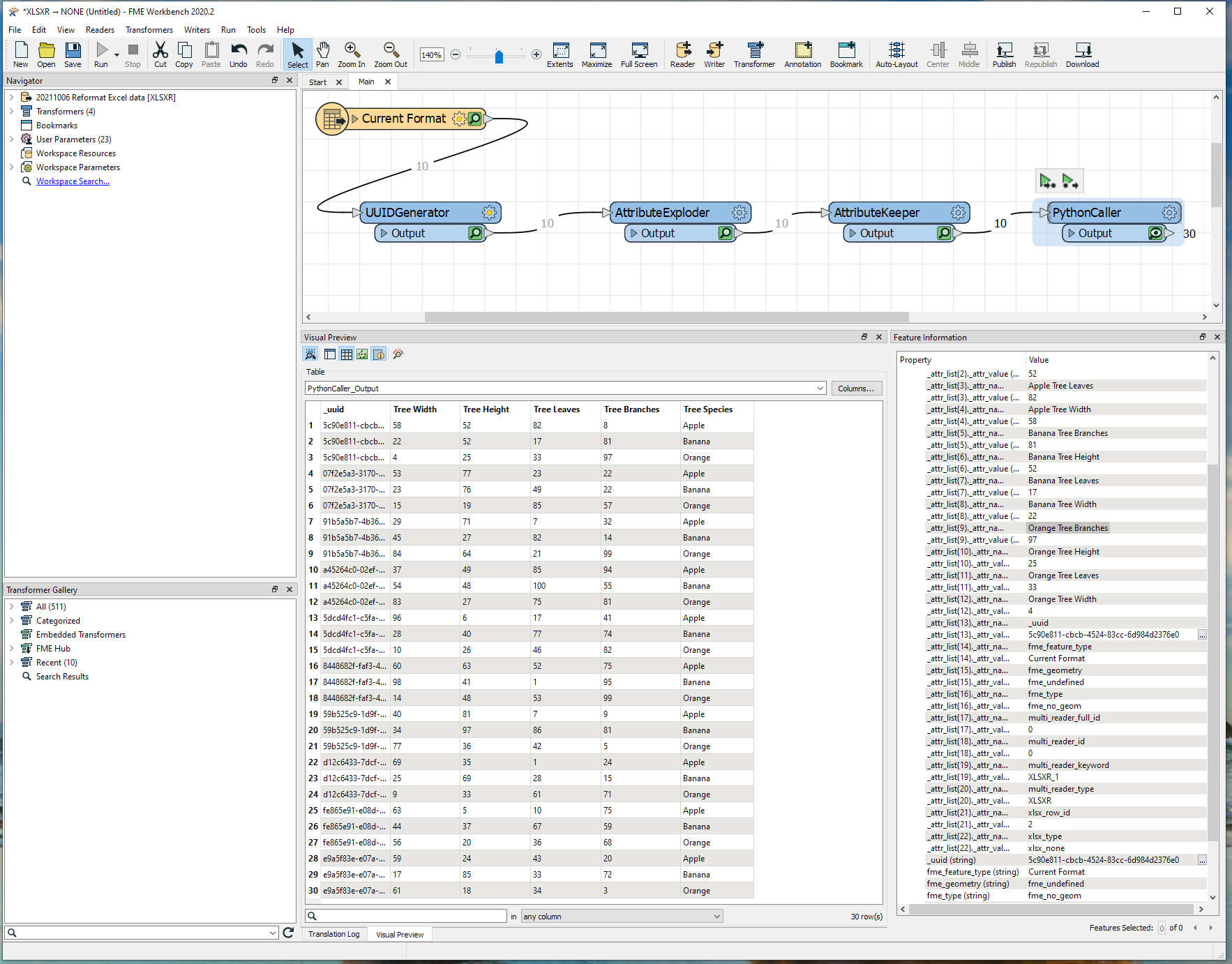
I have been given a huge spreadsheet containing countless series of identical columns that are duplicated many times, with a prefix in front of each that indicates some kind of property of the data. I now want to reformat these data so that the duplicate columns are replaced with unique columns and the attributes that were used to separate the columns become attributes in the data instead. Please see simplified attachment (and screenshot, below) which shows the "Current format" and "Desired format" sheets.
Current
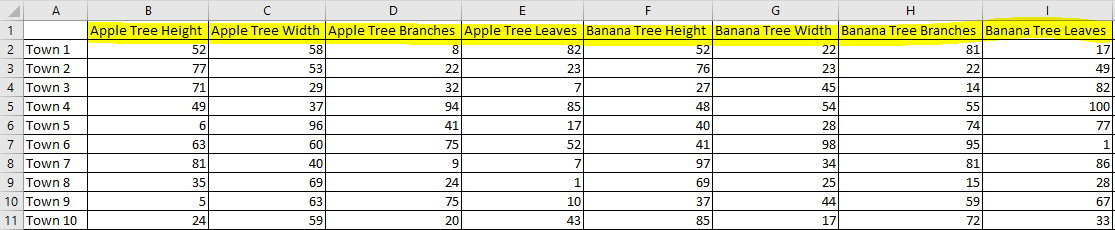 Desired
Desired
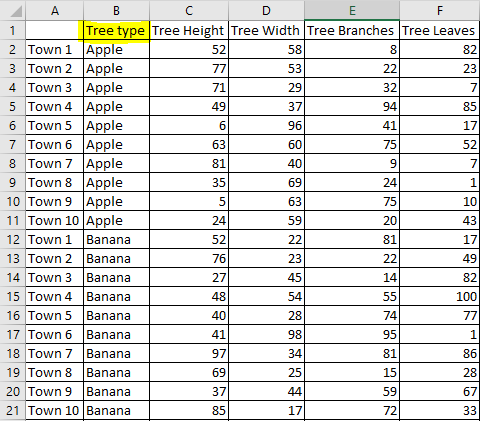
I've tried several things, none of which are giving me the results I want:
- Adding an AttributeCreator to create a separate, duplicated pipeline for each of the types (Apple, Banana, Orange, etc.) and then BulkAttributeRenamer on each to remove the prefix of the column based on the attribute I created. In theory, this should create a single "Tree Height", etc. column per pipeline that can then be merged back together and the remaining attributes discarded but this doesn't work because it doesn't rename the columns correctly using the new attribute.
- Using an AttributeExploder to write the attributenames to attributes, then using an AttributeCreator to create a separate, duplicated pipeline for each of the types (Apple, Banana, Orange, etc.). I then merged these back together into a string replacer to remove the "type" from the attributes and used an AttributeKeeper the cleaned attributes, e.g. "Tree Height", etc. This takes too long to run and quickly reaches tens of millions of rows. It is also quite complicated to recreate the table in a sensible structure at the end
- Adding an AttributeCreator to create a separate, duplicated pipeline for each of the types (Apple, Banana, Orange, etc.) and then using a BulkAttributeRemover to only keep the columns that contain the value of the attribute I created. Unfortunately, the REGEX does not allow an attribute value to be used in the search criteria so this would require hard coding for every Apple, Banana, Orange, etc.
Ideally, I'd like to be able to read in a table of all of the prefixes (e.g. "Apple", "Banana", "Orange" in this case) and reformat the table automatically by using their values. Whatever the solution, it needs to be relatively scalable because the spreadsheet is huge! Any help gratefully received, cheers
Best answer by comelio
View original

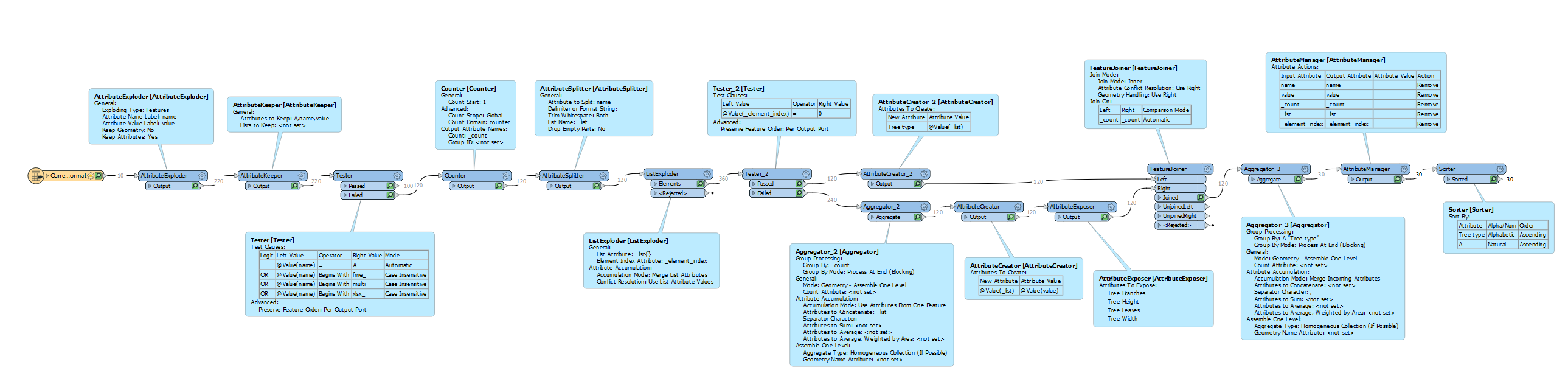 Result:
Result: