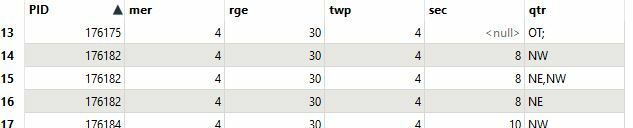
I have a dataset which came with duplicates in what I need to be a join column (PID) therefore unique. How can I filter and remove the duplicate rows based on some rules. In this case I want to keep the consolidated value (NE,NW) in the qtr column and remove the other two rows with the common PID of 176182. (Shown above and below the row I wish to keep.)