Scenario:
Assuming A = 1, B= 3, C=4, How do I use FME to work out the rest of the blanks

Much Appreciated

Scenario:
Assuming A = 1, B= 3, C=4, How do I use FME to work out the rest of the blanks
Much Appreciated


 +17
+17
To start... not a very helpful topic title here.
This sounds like a school puzzle the way you present it. What is your start file and what is the result?
I guess the start is this table:
A;1
A;
A;
B;3
B;
C;4
C;
And the result would be:
A;1
A;1
A;1
B;3
B;3
C;4
C;4
The easiest way is Sorter by Column1,Column2 , then use an AttributeCreator and set the Enable Adjacent Feature Attributes Checkbox. Number of Prior Features: 1
Then set the Attribute Value to ConditionalValue
And the conditional statement to If Column1 = feature[-1].Column1 and not Column2 has Value then Column2 = feature[-1].Column2
Or you could use a FeatureMerger. Test if Column 2 has a Value, if yes then feed it to the Supplier, if not feed it to the Requestor. To make it more robust you can feed everything to the Requestor and before the FeatureMerger-Requestor remove Attribute Column2 and before the FeatureMerger-Supplier remove all Keep only Column1 and Column2.
See my attached workspace
 +1
+1
Hi @calvin - this is a good case for the variablesetter and retriever! I've attached a workspace and some sample data. Every time we get a feature in the tester which has a count, we set that as the globally reachable value. The other features, go to the retriever and pick up that value. As long as the input is ordered the way you had it in the example, this works fine.

 +25
+25
Hi @calvin - this is a good case for the variablesetter and retriever! I've attached a workspace and some sample data. Every time we get a feature in the tester which has a count, we set that as the globally reachable value. The other features, go to the retriever and pick up that value. As long as the input is ordered the way you had it in the example, this works fine.
Personally, I would avoid the VariableSetter and Retriever (sorry). Instead, I would use the Advanced Attributes > Enable Adjact Features option. Select 1 prior feature. For your actual attribute, you set it to conditional. If it has a value already, leave that value. If it has no value, then use the one from the previous feature.
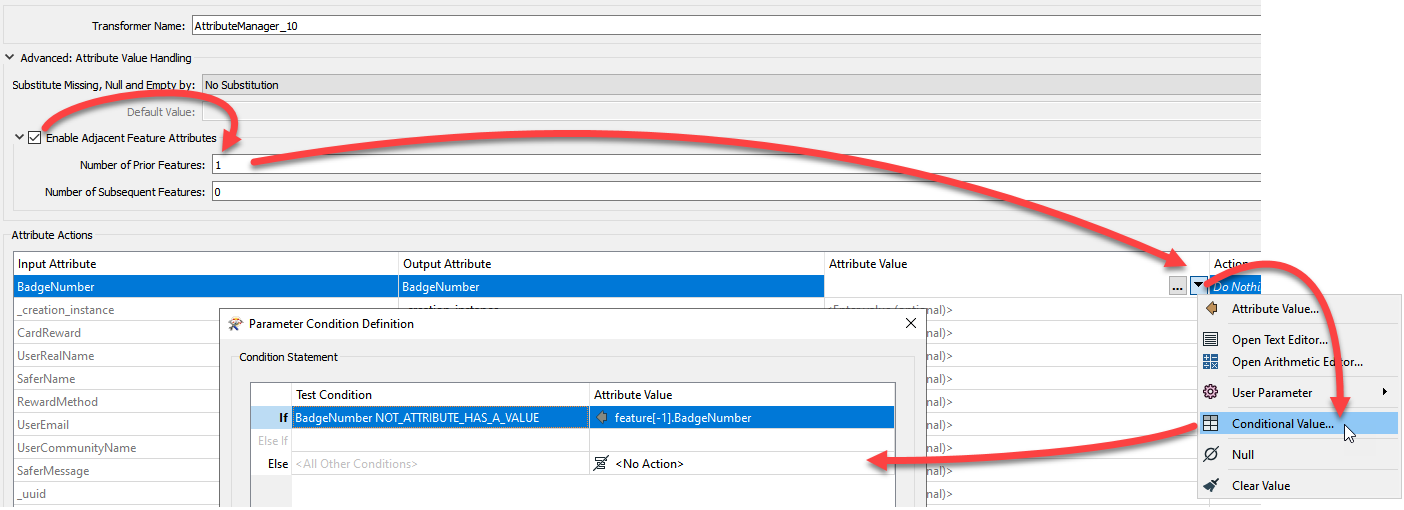
That is just as simple and you don't need to worry so much about the flow of features being consistent (which can be a problem with Variables).
+1
Personally, I would avoid the VariableSetter and Retriever (sorry). Instead, I would use the Advanced Attributes > Enable Adjact Features option. Select 1 prior feature. For your actual attribute, you set it to conditional. If it has a value already, leave that value. If it has no value, then use the one from the previous feature.
That is just as simple and you don't need to worry so much about the flow of features being consistent (which can be a problem with Variables).
Hi Mark!
I think you're right in this case, that adjacent features is perhaps more straightforward. When looking at workspaces, though, I find the adjacent features to be a pattern that's more difficult to see at first glance. Perhaps, that's more of a comment on my documentation standard than the transformers themselves. : ) Do you have a case where you think the setter/retriever is a neat solution?
+25
Personally, I would avoid the VariableSetter and Retriever (sorry). Instead, I would use the Advanced Attributes > Enable Adjact Features option. Select 1 prior feature. For your actual attribute, you set it to conditional. If it has a value already, leave that value. If it has no value, then use the one from the previous feature.
That is just as simple and you don't need to worry so much about the flow of features being consistent (which can be a problem with Variables).
Yes, "adjacent features" isn't as easy to find as I'd like, but I'm not sure what we can do about that. As for the setter/retriever, I really try to avoid them because, with streams and bulk-mode/feature tables, it can have more problems than before.
I think variables could help when the features passing information aren't adjacent, or even close to being adjacent. Here we needed the information for every feature, so we could keep passing it on like a relay runner. But if we wanted to pass information from feature 1 to feature 10,000... well we wouldn't want to record 10,000 prior features and we wouldn't really want to pass it on to every record.
But even then, in most cases, I could use a FeatureMerger instead, especially if the information is needed later in the workspace, not earlier.
So if I were to use variables, it would probably need to be:
I'm sure there are some good scenarios, I'm just really struggling to think of one right now!
Enter your username or e-mail address. We'll send you an e-mail with instructions to reset your password.

