Hello,
I have several textfiles which have filenames such as this with varying numbers:
2017061_XXX_6183378N_568614E_20170708_001.asvp
Inside the files is a header which is crucial that it is not altered as well as two columns of data:
( SoundVelocity 1.0 0 201707081732 0.0 0.0 -1 0 0 KM_DEFAULT E 0205 )
0.458 1475.522
0.379 1475.532
0.354 1475.523
0.393 1475.525
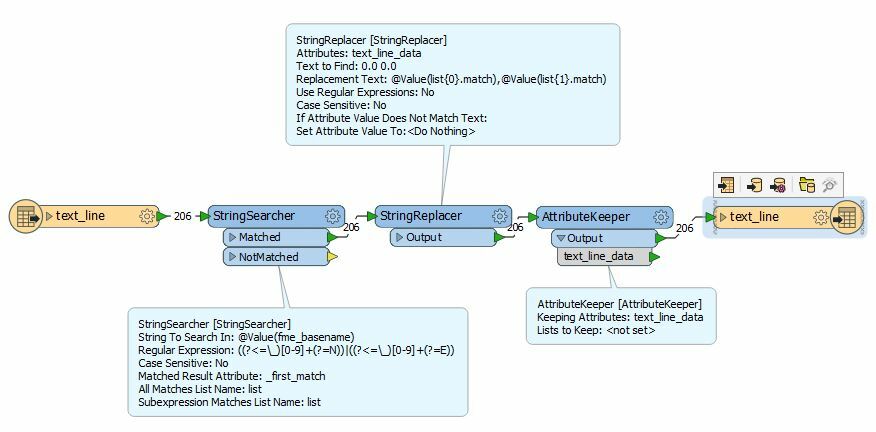
I need to extract the 6183378 and 568614 from each file and its filename, these numbers varies for each file since they are Y and X coordinates. This task is simple and I have done that in another workflow which builds a list of files. However what I need for this workflow is that it replaces just the 0.0 0.0 in the header with the coordinate values from the filename, this needs to be done on multiple files without making any other changes on the file contents or its delimiters.
I have tried several ways which includes bringing the textfile in as CSV and try to rename the attribute with a list value to no success. I have tried importing as a CAT and use stringreplacer in combination with my previous workflow of extracting the values. However I have not succeeded in this, I have just been able to populate the entire column below 0.0 0.0 with the values.
I have attached one of the files as a .ZIP if someone wants to try to help me.
Regards,
Robin