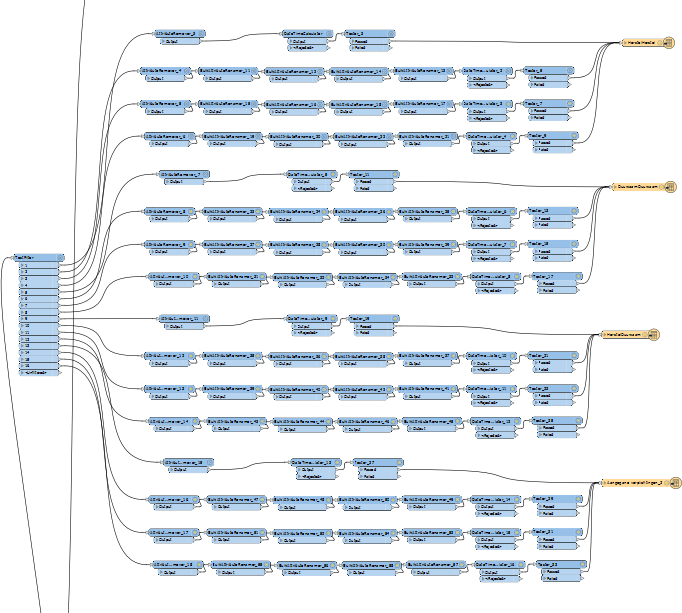
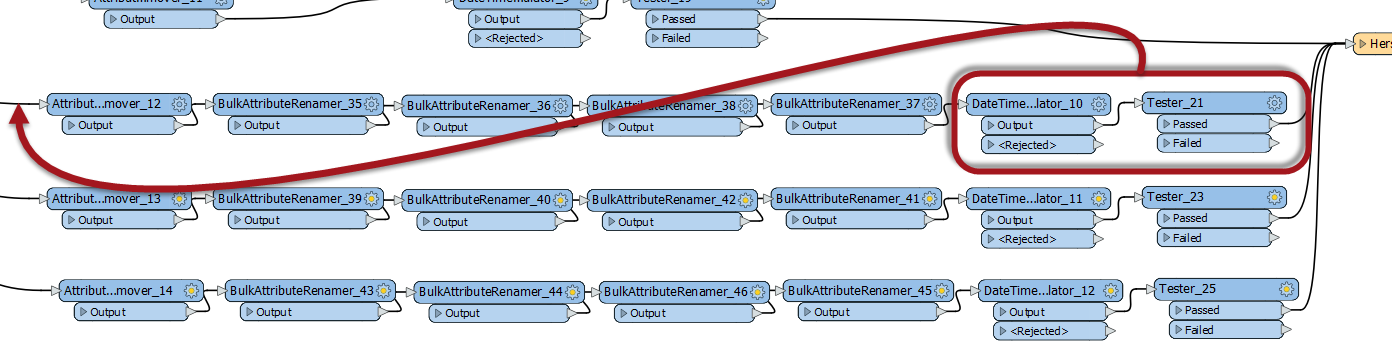
The attached workspace contains of two parts.
In part 1 I transform an excel document which contains many records of clients and products. Some clients have had only one product, others might have had 10. The result is also an excel document in which each client has only one row. In the row the order of al te products is displayed in time starting with the first product and ending with the last product (in time).
In part 2 some checks are done on the data. For example some products of the same categorie may not be handed out within a short time period.
The workspace does the trick, but is quite slow. I think things could be made more efficient using loops. I've done some research on the internet but can't find the solution yet. Any help would be appreciated.
Best answer by mark2atsafe
View original