Hi Everyone,
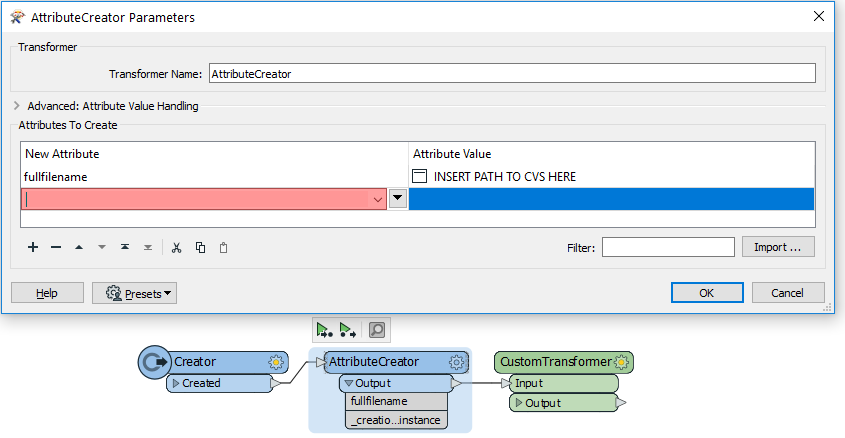
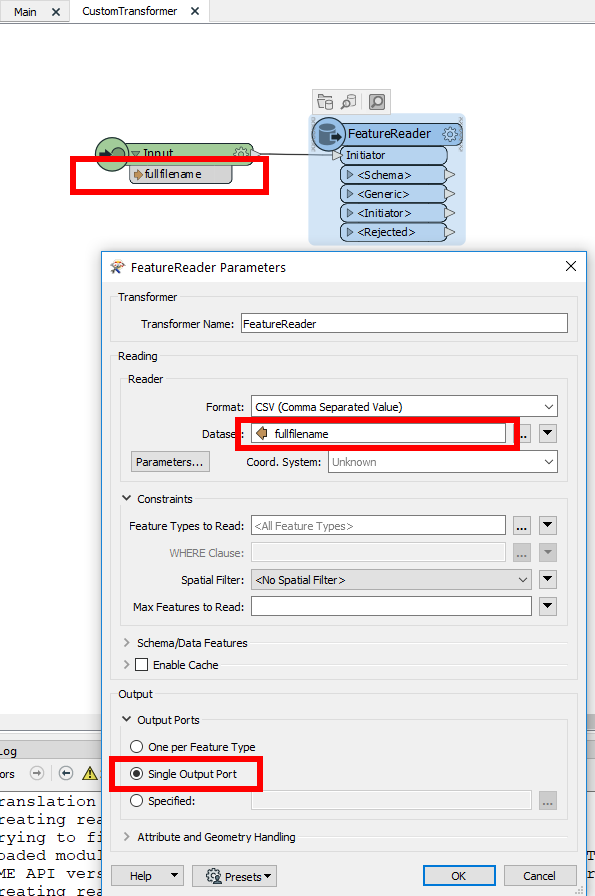
I tried to make use of the schemamapper transformer to create a new output excel spreadsheet which takes a customised schema csv file as an input. The problem is that the schema file sits within a random folder (date time stamp temp folder name - e.g. 20190903100000) each time the workbench run. (PS: the randomised folder is created at the beginning of the workflow and being passed through as an attribute value).Due to the randomised temp folder name which i tried to pass into the schemamapper as the dataset, I am not able to pass it through. I then tried to create a custom transformer where i can pass the temp folder name via attribute value > published parameter for the custom transformer. The new problem I have now is that the custom transformer does not appear to be able to pick up the attribute value (which has become a published parameter) in the dataset field within the schemamapper.
It always throws an error shows "ERROR |CSV reader: Failed to open file '@Value(working_folder)Schema.csv' for reading. Please ensure that the file exists and you have sufficient privileges to read it"
Can anyone advise what would be the best method to approach this?
Note that I am aware that I can initiate another workbench which works perfectly but I would like to keep it in a single workbench.
Please find attached sample workbench.
Thanks you everyone for your assistance.