Hello,
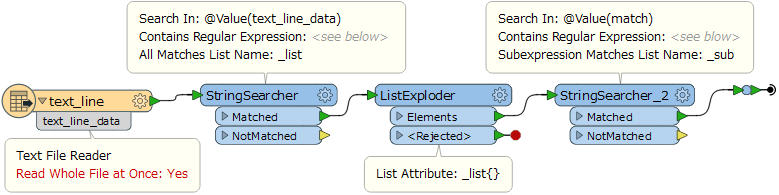
I'm attempting to extract strings from a text file that comes after specific key words.
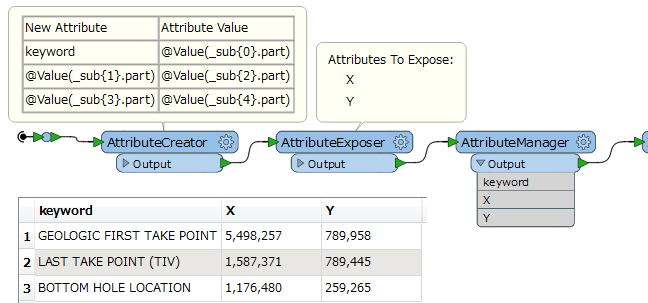
I only need to extract the X,Y coordinates from the text but I need to preserve what values they correspond with. In my example these are well points and I will need to keep the location for each one.
I have the following keywords:
GEOLOGIC FIRST TAKE POINT:
BOTTOM HOLE LOCATION:
LAST TAKE POINT (TIV):
I only need the X,Y coordinates that come after these key words, but I'm having trouble getting my regex expression to pull the X,Y data following each key word as there is text in between I don't need.
I've attached a sample of my data below.
FIRST TAKE POINT /
GEOLOGIC FIRST TAKE POINT:
WORDS IN BETWEEN WHAT I WANT TO EXTRACT
X = 5,498,257'
Y = 789,958'
LAT
LONG
LAT
LONG
(NAD27)
(NAD83/86)
LEGEND:
(PSL) - PROPOSED SURFACE LOCATION
(PP) - PENETRATION POINT
(FTP) - FIRST TAKE POINT
(GFTP) - GEOLOGIC FIRST TAKE POINT
(LTP) - LAST TAKE POINT
(BHL) - BOTTOM HOLE LOCATION
(r) - RADIUS
(TIV) - TOE INITIATOR VALVE
- APPROXIMATE SURVEY LINE
- UNIT LINE
- PROPOSED BORE PATH
- AS-DRILLED BORE PATH
- PROPOSED POINTS
- AS-DRILLED POINTS
LAST TAKE POINT (TIV):
TEXT HERE IN BETWEEN WHAT I WANT
X = 1,587,371'
Y = 789,445'
LAT
LONG
LAT
LONG
(NAD27)
(NAD27)
(NAD83/86)
BOTTOM HOLE LOCATION:
TEXT HERE
X = 1,176,480'
Y = 259,265'
LAT
LONG
LAT
LONG
Best answer by takashi
View original