Hello,
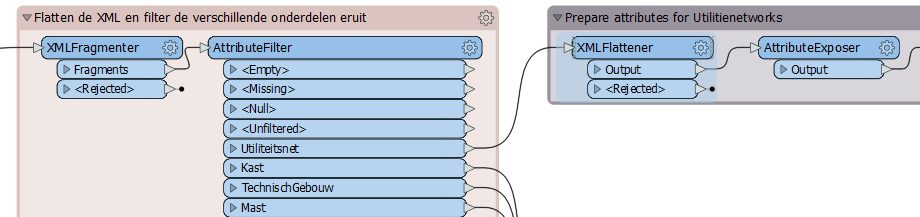
I am dealing with XML files that contain more than 300 attributes deeply nested within lists, and the records present point data. The final goal is to extract and flatten all the data that is there and covert it further into a gdb. What I was doing so far was flatten the XML through the XML reader, and then use Attribute Exposer to expose as many lists and list elements as possible. However this is quite time consuming since every element contains lists that need to get exposed, and does not create a unique solution for all the XMLs that I have. Moreover, the extent is different in every XML, for example I choose to expose certain elements based on a reference XML file:
Content.Base.Relationshiplist.Relationship.Referencelist.Reference{0}.ReferenceID
Content.Base.Relationshiplist.Relationship.Referencelist.Reference{0}.ReferenceID.type
Content.Base.Relationshiplist.Relationship.Referencelist.Reference{0}.ReferenceID.primary
Content.Base.Relationshiplist.Relationship.Referencelist.Reference{1}.ReferenceID
Content.Base.Relationshiplist.Relationship.Referencelist.Reference{1}.ReferenceID.type
Content.Base.Relationshiplist.Relationship.Referencelist.Reference{1}.ReferenceID.primary
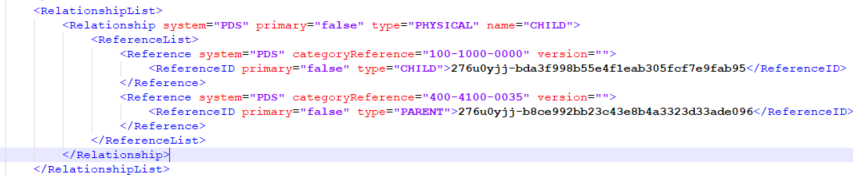
However, another XML could have more than just two elements in this list, and with this definition those would not be included.
Is there way to extract/expose all list attributes from a flattened XML file?
Thank you in advance.