Hello,
I am struggling to read a very simple table from a PDF, I just want to have something in the output.
I have turn on only the "Read Tagged Tables" in the Reader's parameters, but nothing is coming out from it. The reader is not being created in my window. I have created a special table from excel in PDF to be sure that the table was fine.
It looks simple in the FME presentation... https://www.safe.com/convert/geospatial-pdf/excel/
Could someone git me a hint about what am I doing wrong?
Thanks!
My simple PDF with its readable table:
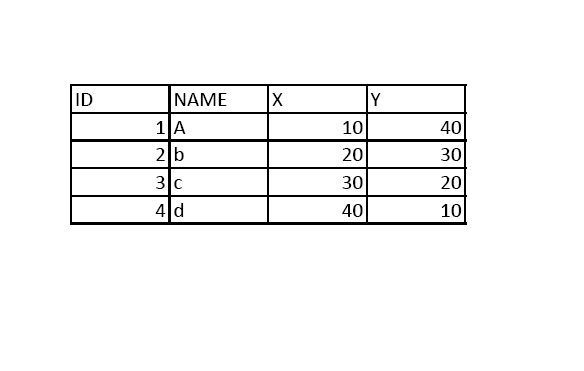
My Reading parameters: