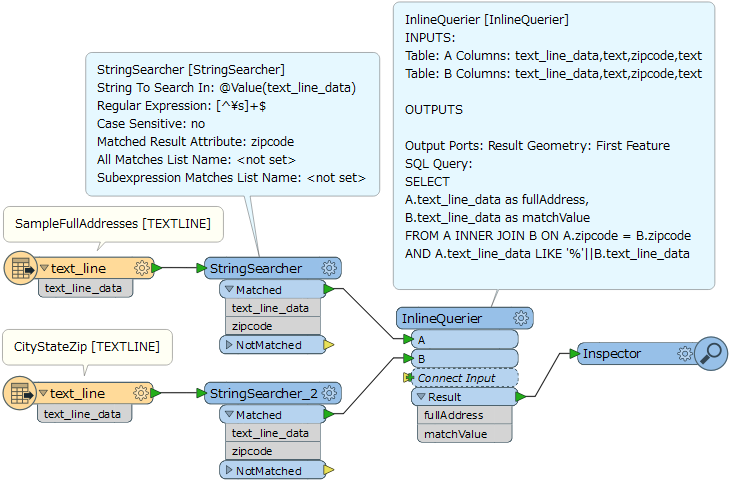
I may have had an aneurysm but I can't figure out how you can evaluate if one list string value is contained in another list of strings.
Some context: For each list string value in List A, I want to cycle through all string values in List B and evaluate whether any string variable within List B is contained within each List A item. Basically, I'm trying to create a nested loop cycling through each of List A once and for each List A item, cycle through List B (a nested loop).
If there is a match [e.g., Line B value(34) matches Line A(15)], then I want to pull that string out of List A(15) and plop it into an attribute and evaluate the next Line A value. Why can't I figure this out in FME? Please be kind.
Also is there any way to plug in an attribute value into the list element index, to aid in looping? I'd like to define this: list{@value(count)} to cycle through the list values, but it only allows user entry of the index number.
Thanks, Pete
PS. Also, I'd like to do this without resorting to Python, if at all possible.