


Text attributes can have a character encoding in FME, as we all know. The encoding that is used is shown in the Data Inspector, for instance:
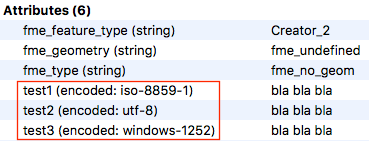
I would like to fetch that "iso-8895-1", "utf-8" or "windows-1252" value. My guess is that the answer is no but the question is: is it possible to extract the encoding somehow? I know that the FME Objects Python API allows me to detect if the attribute is an encoded string (FMEFeature.getAttributeType() ==> FME_ATTR_ENCODED_STRING), but it doesn't tell me what the encoding is. It seems to be stored as a (hidden) attribute property though, otherwise the Data Inspector could not show it.
Depending on the answer(s) I will get here, I'm thinking of posting an idea for an EncodingExtractor transformer.




