
I would like to create new attributes for all features with a value of null. The tricky part is that the number of these attributes and their names is not known before running the workflow. The names have to be equal to the feature values provided by some part of the workflow. I attach an image of what I am trying to do:
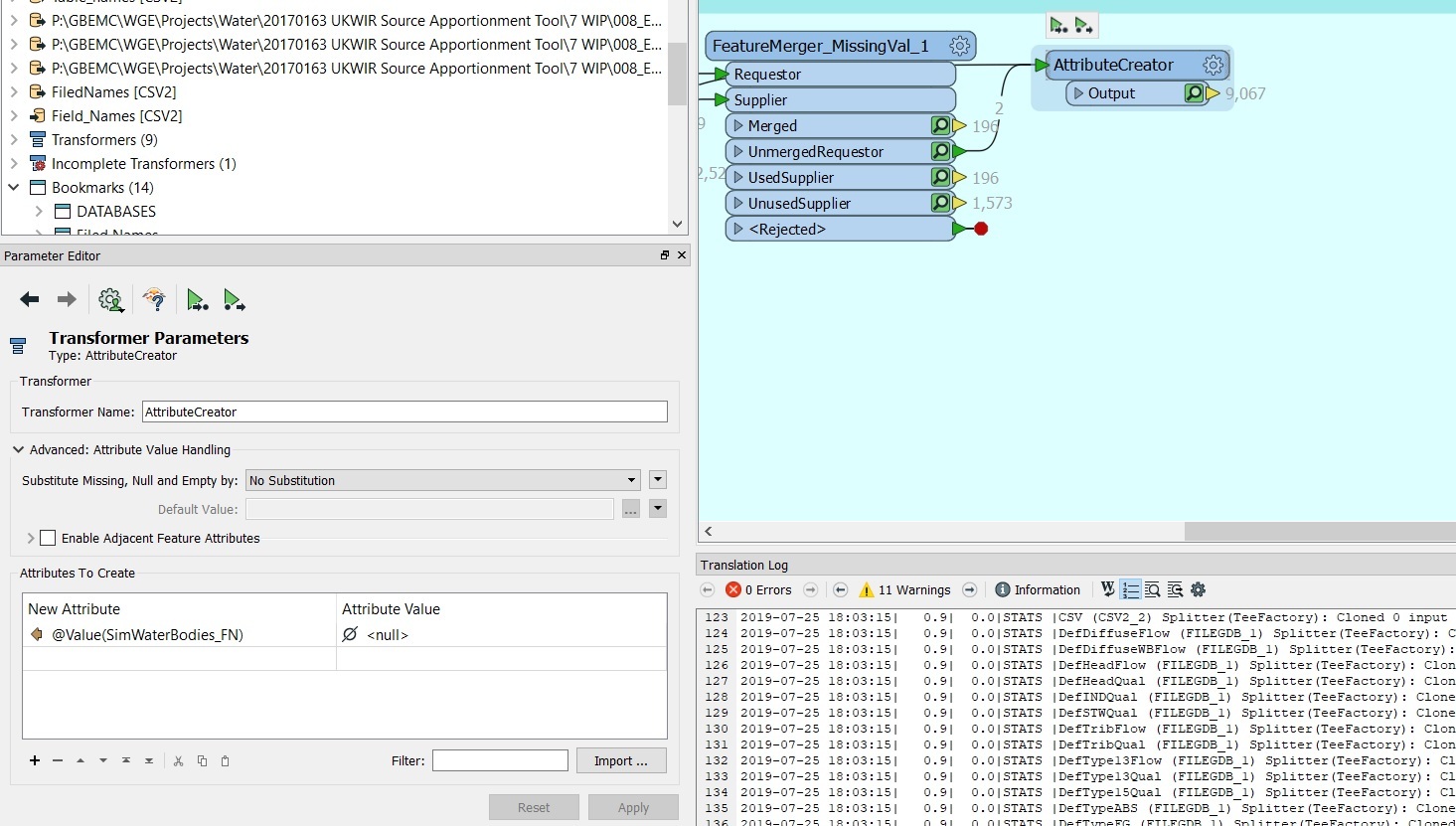 I am feeding the AttributeCreator with the main table (the one where I want to have new attributes --or columns -- with null values) and with the UnmergedRequestor of the Feature Merger. The feature values of SimWaterBodies_FN (the output of the UnmergedRequestor) are supposed to be the names of the new attributes (2 in this case) of the table.
I am feeding the AttributeCreator with the main table (the one where I want to have new attributes --or columns -- with null values) and with the UnmergedRequestor of the Feature Merger. The feature values of SimWaterBodies_FN (the output of the UnmergedRequestor) are supposed to be the names of the new attributes (2 in this case) of the table.I have tried by setting @Value(SimWaterBodies_FN) as the New Attribute and null as the Attribute Value of the Attribute Creator, but this doesn't create the 2 columns with same length of the main Table.
Here is a simple example of what I am trying to do:
Let's say this is the main Table initially:
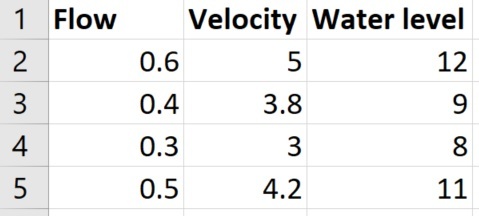
When I run my workflow, the feature merger gives me the following output through the UnmergedRequestor:
 These 2 values (Phophate and Ammonia) of SimWaterBodies_FN are the attributes that I have detected as "not present" in the main table. These depend on one of my input files, so if I change the input file it could be that SimWaterBodies_FN has more or less than 2 values.
These 2 values (Phophate and Ammonia) of SimWaterBodies_FN are the attributes that I have detected as "not present" in the main table. These depend on one of my input files, so if I change the input file it could be that SimWaterBodies_FN has more or less than 2 values.
The output I would like to obtain is the following:
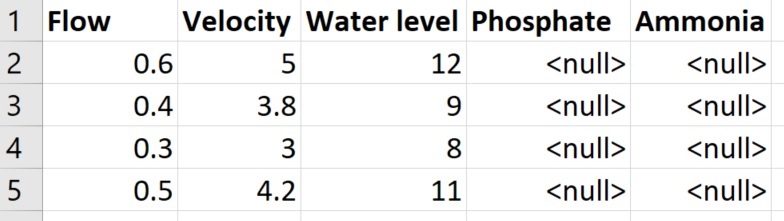
Basically, that 2 attributes are added to the main table with the names of the values of SimWaterBodies_FN, and with all values = <null> (This is not that critical, the value could be <empty>, 999, or other ...).
Thanks for the help.
Best answer by mark2atsafe
View original




