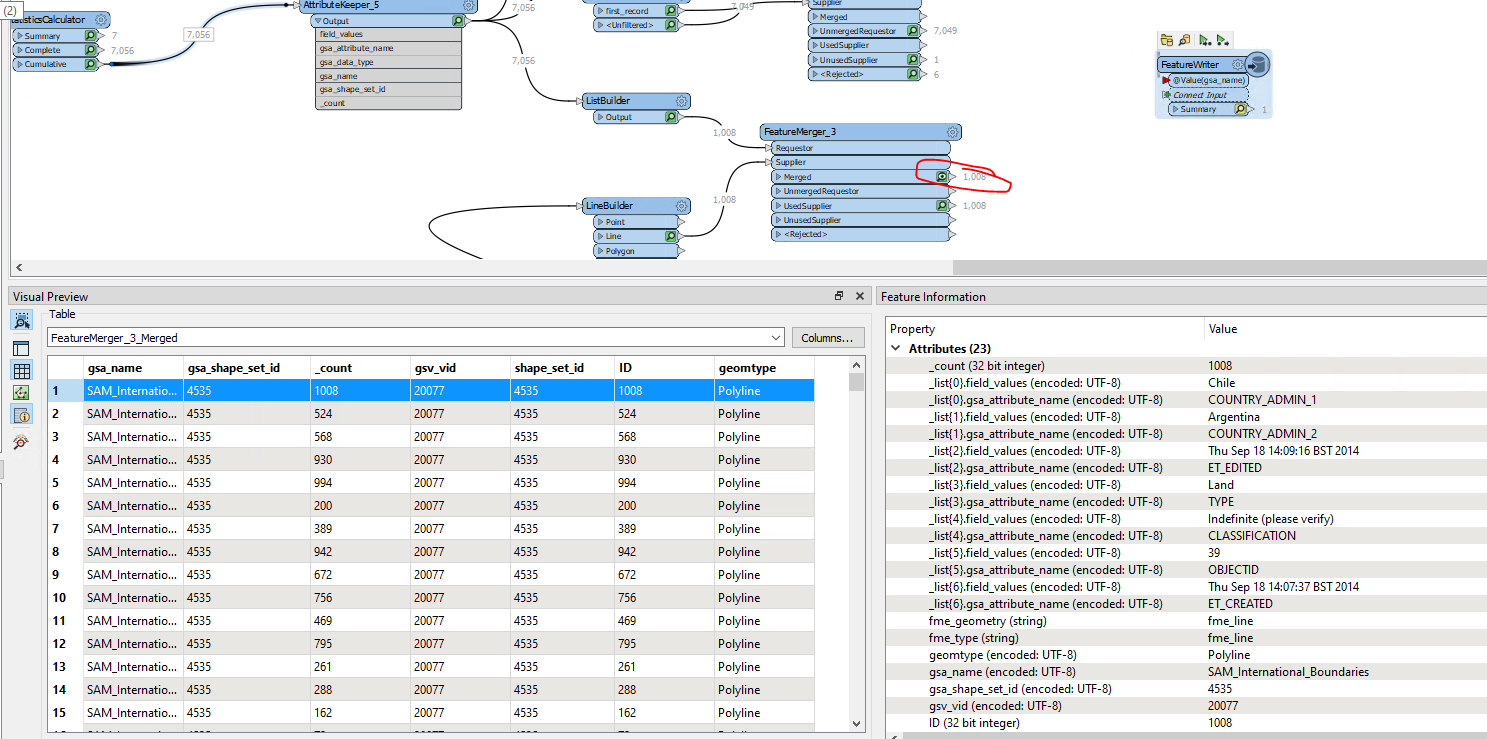
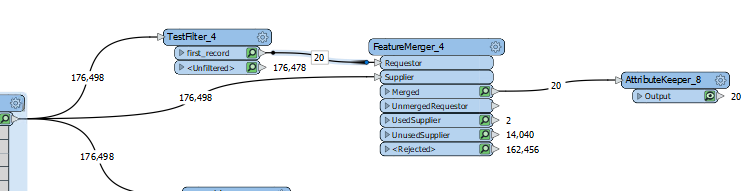
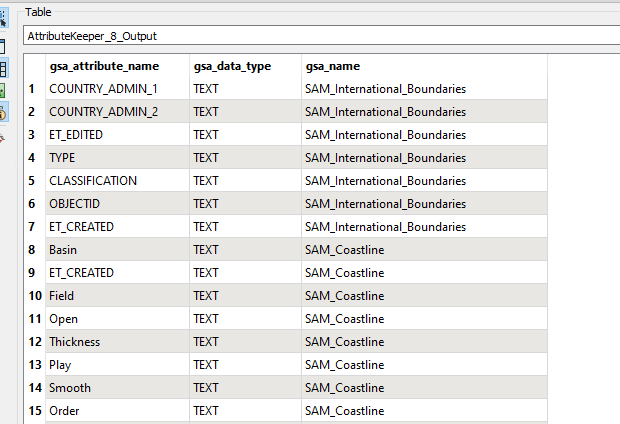
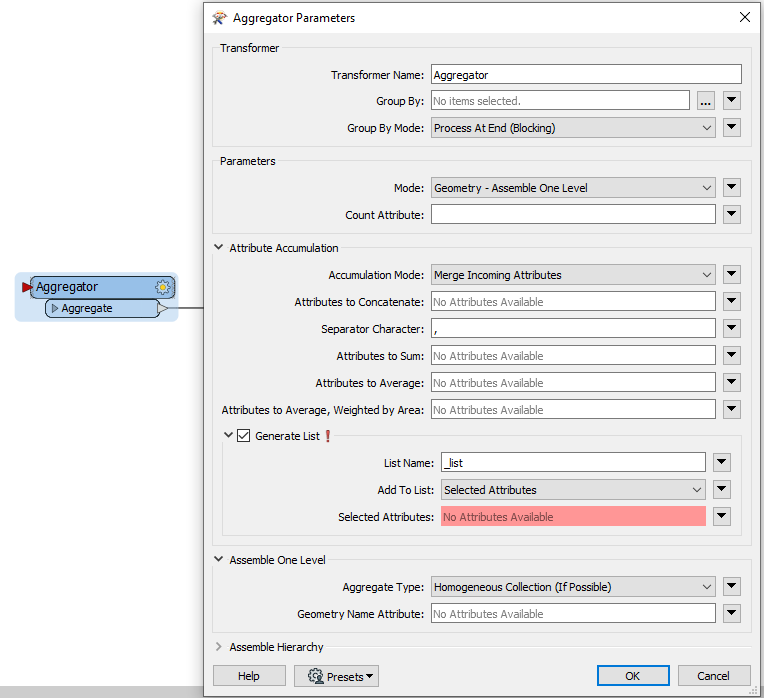
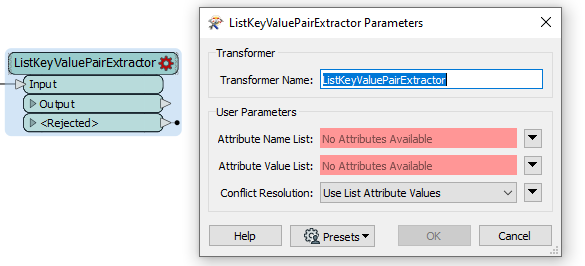
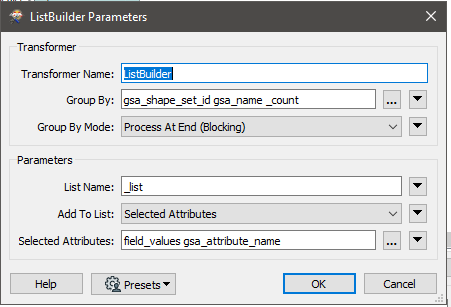
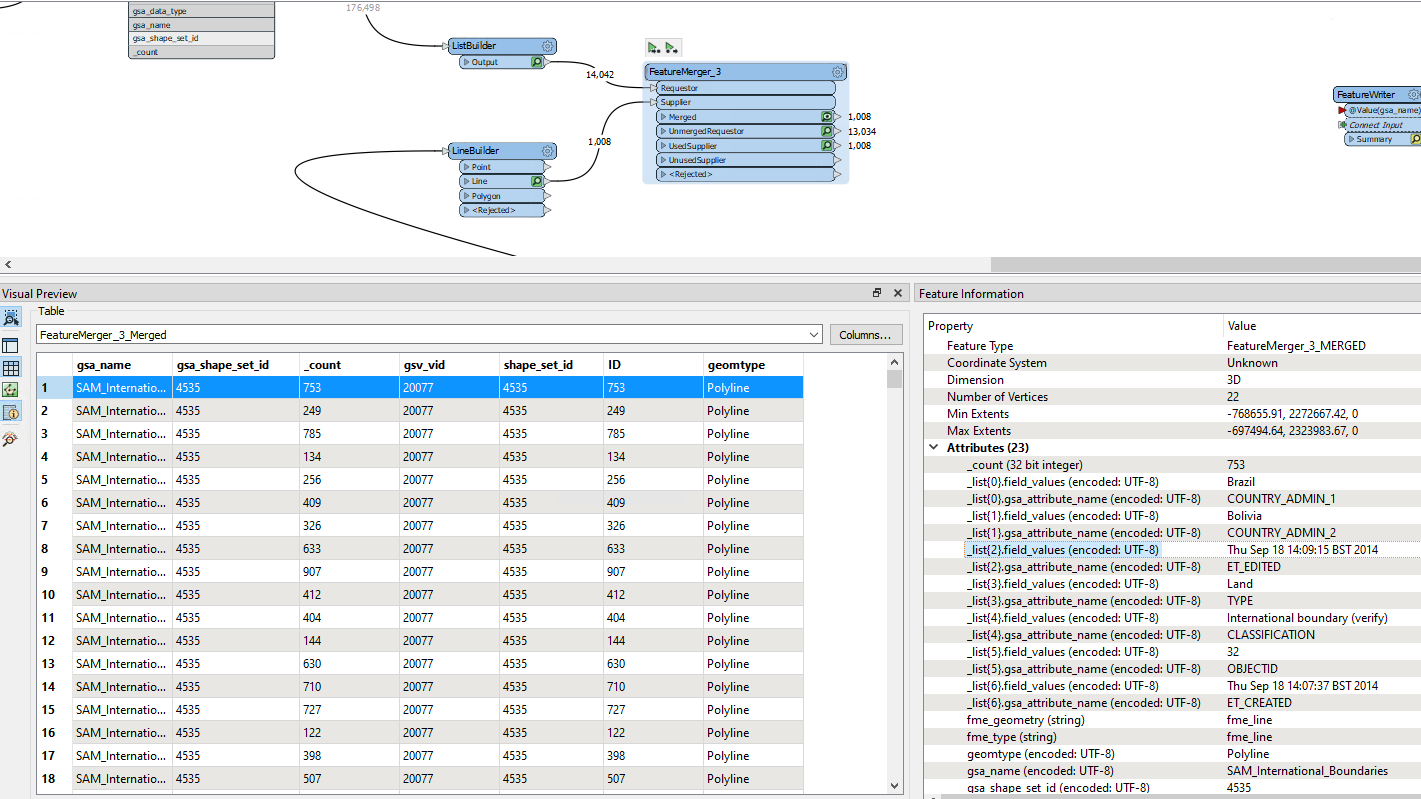
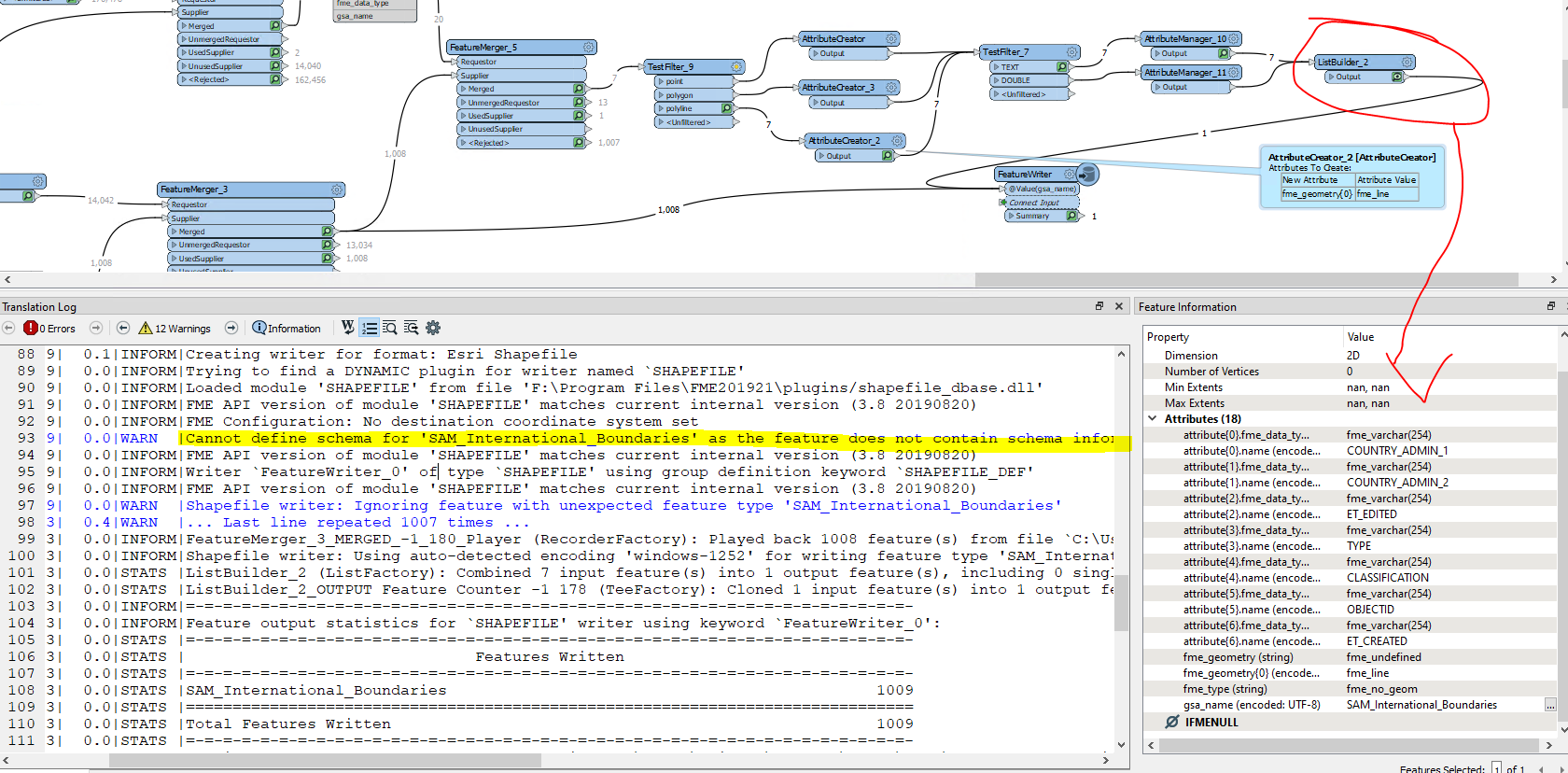
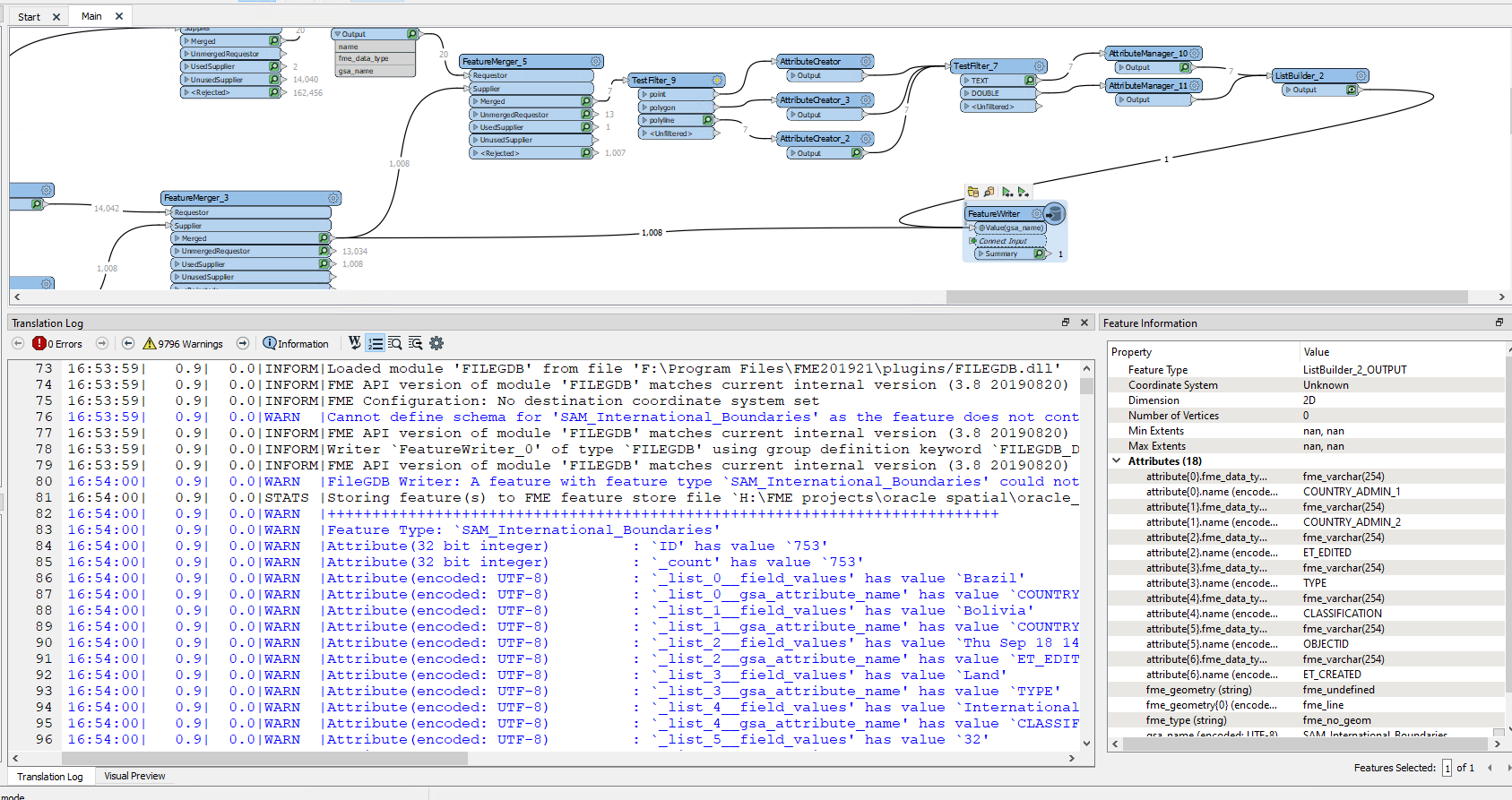
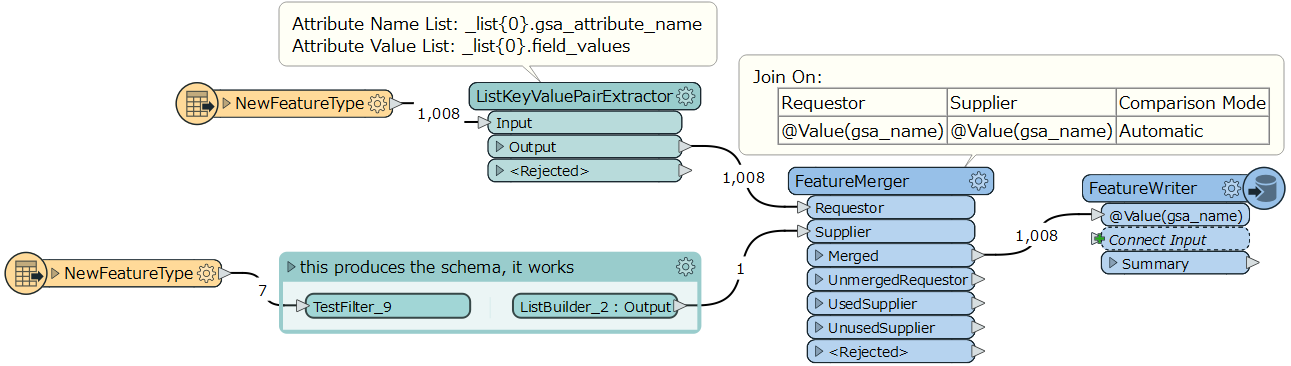
I have a range of features e.g. coastlines, country borders each with different attributes. These attributes are currently available in a table under the following structure:
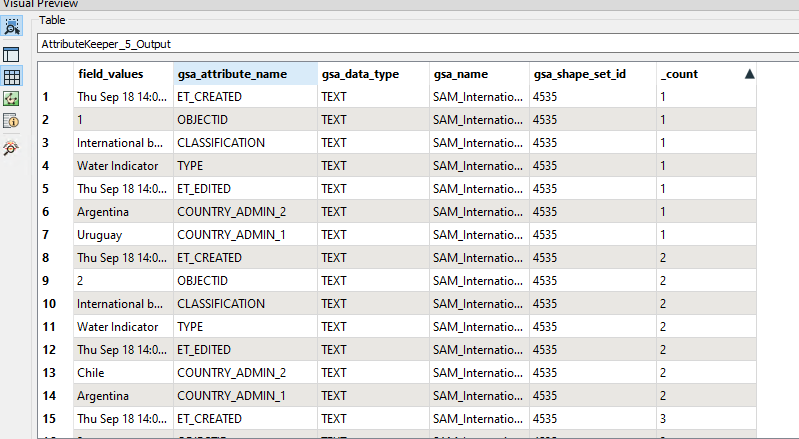
Each feature type has a different set of attributes and I can tie the attributes to the geometry using the gsa_shape_set_id.
How do I turn this flat table in to attributes dynamically adjusting for the schema of each feature? There are thousands of different features and I don't know the schema before this point.
Many Thanks
Oliver
Best answer by takashi
View original