

I am really a neophyte at SQL so could use some help. I have 2 tables, my primary data is a dgn file and the table to update from is an Excel spreadsheet.
dgn file:
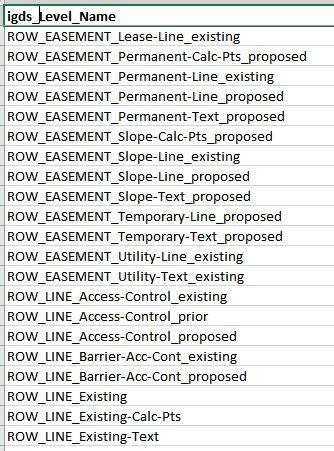
excel:
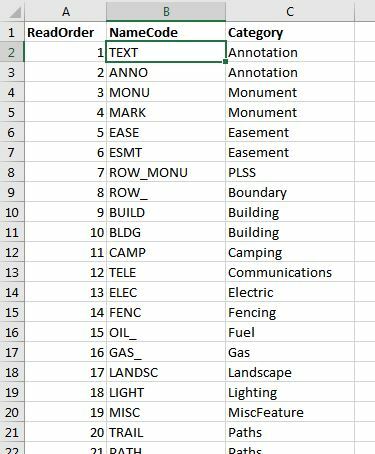
I want to join the excel to the dgn file when the first 12 characters of igds_level_name contains the NameCode in the Excel file. I will then update the dgn.Category from the excel.Category. My output should only be the dgn file.
The last attempt at making this work:
SELECT * FROM Output
LEFT JOIN "US36_dgn_Categories00" ON (SUBSTR("igds_level_name",1,12) LIKE "US36_dgn_Categories00"."NameCode")
SET "Output"."Category" = "US36_dgn_Categories00"."Category" 




