
Hi,
I faced with issue: regex with cyrillic symbols don't return any 'found' result in ListSearcher, while it works for StringSearcher and in Regex Editor test.
Regular expression: (?i:^??\\.?????\\s?\\d+\\/?\\d*\\s?[?-??-?]?$)
Test list values:
_list_{0} (encoded: UTF-8): ??????? ?????????? ??
_list_{1} (encoded: UTF-8): ??? 1?
_list_{2} (encoded: UTF-8): ??? "????????"
_list_{3} (encoded: UTF-8): 2 ????
Expected result: Regex should match on string _list_{1} (encoded: UTF-8): ??? 1? and index attribute should be set to 1.
Parameters of ListSearcher on below picture:
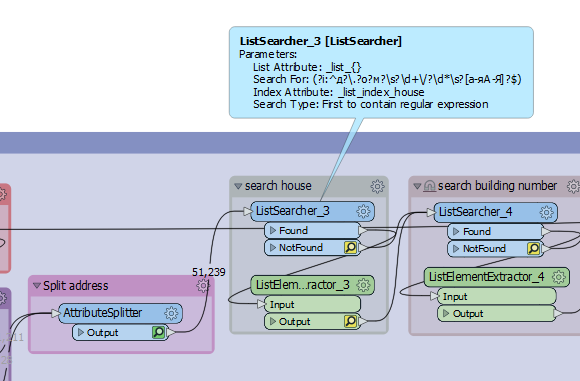
I have checked other regex without cyrillic and it return result in ListSearcher. So I wonder is that any issue with handling regex with cyrillic inside ListSearcher or it is something else?
Thanks in advance for answers!




