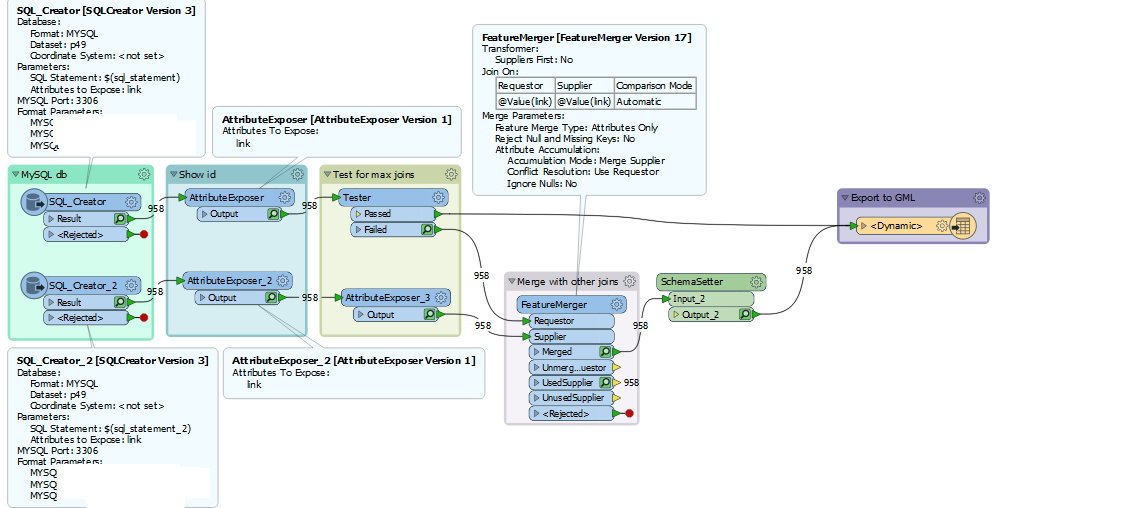
I'm generating a large GML based on data that i get from the SQL creator. The whole workbench is meant to be database driven. There is a main workflow that triggers this one:
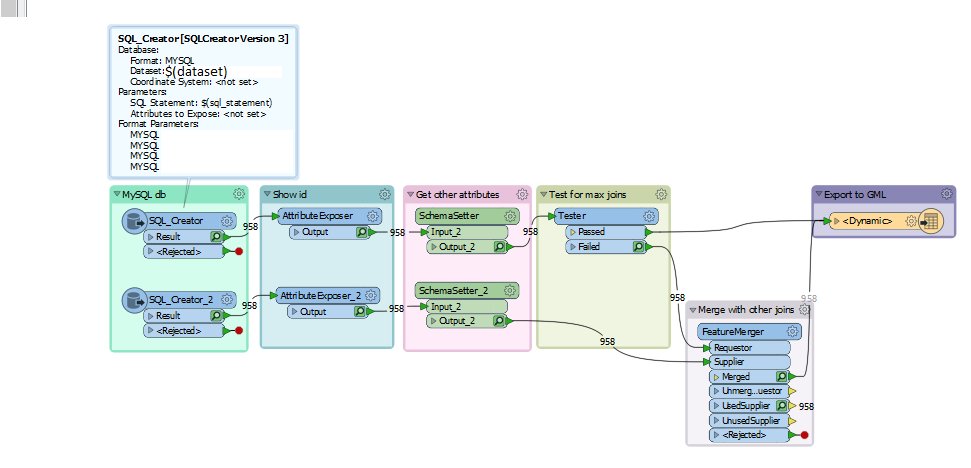
SQL_creator has dataset part A and SQL_creator2 contain part B, both are the same dataset and should be merged by ID (only attribute that they both have). They are split because of the amount of joins that the SQLcreator can handle is reached.
I have a parameter $(sql_statement) that contains the SQL statement that is used in the SQL Creator. The attributes itself are dynamically named, so they cannot be exposed by setting value "attributes to expose". The Attribute exposer exposes the ID of the records, this is the only attribute that both creators have in common.
Schemasetter exposes the dynamic attributes so they will be exported in the dynamic GML export.
It works with the tester directly to GML but it does not show the dynamically created attributes that are created with the SQL_creator2 after the merge is done. Is there a solution to take these attributes into account and join them together and also show them in the GML?
Best answer by jeroen
View original