Hi, good FME people!
First post here, let's see if we can solve this.
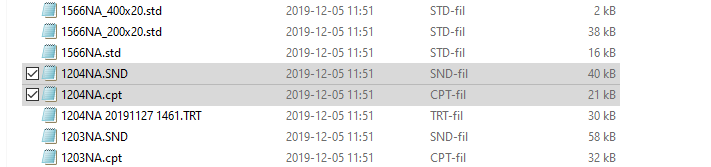
I am using a CSV reader to read all the files within a folder. [...\\rawdata\\*}], regardless of file extension.
In the reader parmeter menu I am using the standard dataset parameter, feature type name from file name.
I am noticing that not all files are getting through the reader. And by checking all unique fme_feature_types against what is actually in the folder it seems that duplicate filenames a skipped.
The problem might be that there are duplicate file names, but in windows explorer, they are not considered duplicates as they have different extensions. Ie "1204NA.SND" and 1204NA.cpt"
Is there a good solution for this?
Thank you in advance
Victor