St. Petters Road is the valid space(it need not be flagged); but
St. Pe tters Road is invalid,
and I need to flag the invalid attributes in a new column as 0 and 1
Can we do that with transformers ?


 +1
+1
St. Petters Road is the valid space(it need not be flagged); but
St. Pe tters Road is invalid,
and I need to flag the invalid attributes in a new column as 0 and 1
Can we do that with transformers ?

 +17
+17
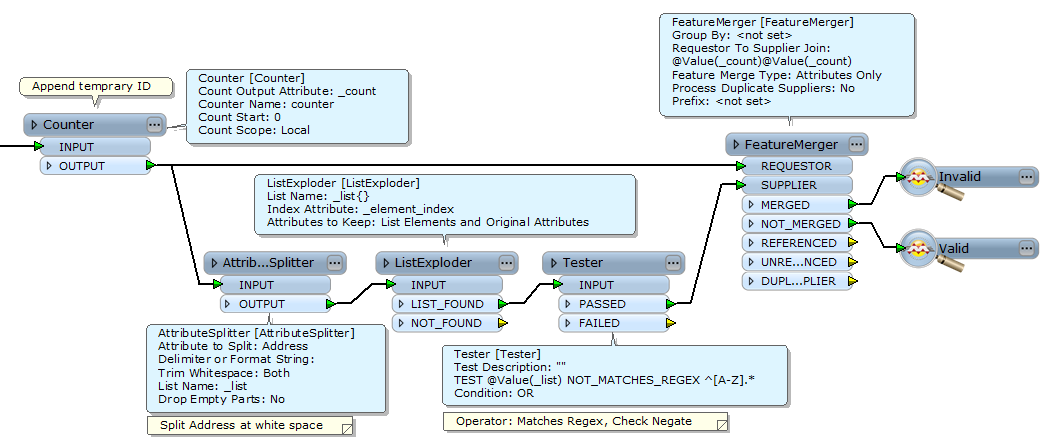
1. AttributeSplitter + ListElementCounter + Tester
1) Split the string at white space (AttributeSplitter).
2) Count output list elements (ListElementCounter).
3) Determine if number of elements is 3 (Tester).
2. StringSearcher
This regular expression matches with the valid format.
-----
^([^\\s]+)\\s([^\\s]+)\\s([^\\s]+)$
-----
Features having valid address will go to MATCHED port.
There should be several other approaches.
+1
Thanks for the reply.
No, there is no certain limit of words for the address. It can be a signle word or as long as 10 words.
+17
If the way to determine can be clarified, it's possible to perform it with machine. Otherwise, it would be difficult.
+17
A valid word always begins with upper case and also an invalid word always begins with lower case?
Do you have a list of valid words?
and so on.


 +13
+1
+13
+1
Ex-
St. Petters Road (The first letter word should be in Caps)
St. Petters road (This will also be valid in that condition, not a problem)
St. Pet ters Road (This will be invalid because the first letter is not in Caps, i.e Pet ters)
+17
 +3
+3
this regexp grabs spaces in front of lowercase letters.
(\\s)+[a-z]+
if u use tcl in a tester the all switch will find em all:
@Evaluate( [regexp -all {(\\s)+[a-z]+} "@Valeu(streetname)]) != 0
There is no way to equalize St. Petters road to St. Petters Road. Unless you have both, like if u had a database with correctly spelled streetnames. But then you would'nt need to find the lowers no more i guess.
Software can't decide wether Pet ters is a valid name or not. Only humans can, if they have a full database at their disposal (or a good and maybe large memory)
Me, i only know a St. Peters road. So to me it would flag invalid.
According to Stephen Donaldson in Cryptonomicron, there are some weird names on this planet...Qghlmn and such...lol.
+17
The workflow I posted was too cluttered one. The workflow can be replaced with only one Tester with this setting.
Left Value | Operator | Right Value | Negate
Address | Matches Regex | .+\\s[^A-Z].* | (uncheck)
Plan B: Use your eyes and hands.
If you can expect that the number of invalid records are not so many, I think partial manual operation could be a quicker solution. For example:
Step 1: Divide the records into valid part and (candidate) invalid part with the Tester.
Step 2: Manually extract valid records from the result which were determined as (candidate) invalid in Step 1.
Step 3: Merge the valid part (Step 1) and the valid records (Step 2) to create final result.
+1
+17
-----
.*\\s[^A-Z].*
-----
If it satisfies your requirement, can be used to filter features (Tester) or to do Conditional Value Setting (AttributeCreator) etc.
+1
I don't bother if the word is correct or not. What all I want is, if there are three words, there should be 2 spaces, if there are 5 words, then 4 spaces-
Ex-
St. Petters Road - It should contain only two spaces (Assuming there are no leading and trailing spaces).
The road name can also be wrong (which can be seen in address component Normalization).
Here, the road name can also be wrong like- St. Petters Ro ad. (Assuming that RO AD are two words, and they are correct).
Simply, there should be (N-1) spaces than the roads (without including lead and trail spaces). Is there any possibility to do that. ??
+17
I'm not sure what is your exact requirement.
You mean these are correct? (there is only one space between every two words)
-----
St.<space>Petters<space>Road
St.<space>Petters<space>Ro<space>ad
-----
and these are wrong? (there are two or more spaces between two words)
-----
St.<space>Petters<space><space>Road
St.<space><space>Petters<space>Road
-----
What about these?
-----
St.<space>Pet<space>ters<space>Road <-- correct?
St.<space>Pet<space><space>ters<space>Road <-- wrong?
-----
+1
Yes, You get it right-
St.<space>Pet<space>ters<space>Road <-- correct?
St.<space>Pet<space><space>ters<space>Road <-- wrong?
If there is more than one space between two words, its incorrect. Only one space is required between the two words.
+17
-----
.*[^\\s]\\s{2,}[^\\s].*
-----
You can use the expression with "Matches Regex" operator as a test condition in the Tester or the AttributeCreator (conditional value setting).
+1
But I didnot get this ---- .*[^\\s]\\s{2,}[^\\s].*
Can you please explain this. Thank you !!
+17
* means 0 or more.
[ ] defines character class.
^ means "non" in a character class definition
\\s represents a white space.
{N,} means N or more than N.
So,
.* --> zero or more any character
[^\\s] --> any character except white space
\\s{2,} --> two or more white spaces
See here to learn more about regular expressions.
http://www.regular-expressions.info/
+1
May be we can also do this task using Tester-
Address (Field Name) Like %__%
where,
__(underscores) are spaces
+17
-----
<space><space>St.<space>Petters<space>Road
St.<space>Petters<space>Road<space><space>
-----
+1
I am trying to find a solution for that, not yet succeeded !!! ):
+17
+17
If you create trimmed address beforehand, can get the same result as the regular expression without changing the original address.
1) AttributeCreator
_trimmed = Address
2) AttributeTrimmer
Attributes to Trim: _trimmed
Trim Type: Both
3) Tester
_trimmed Like %__%
Enter your username or e-mail address. We'll send you an e-mail with instructions to reset your password.

