Hi,
I have a database with FIRST_NAME, NAME and BIRTH_DATE.
I have to find all the potentially duplicate people.
If I find two features with FIRST_NAME and NAME written the same way or looks similar, I have to compare the features between each other to check if they have the same BIRTH_DATE. If they do, it's the same person, if they don't it's two different people.
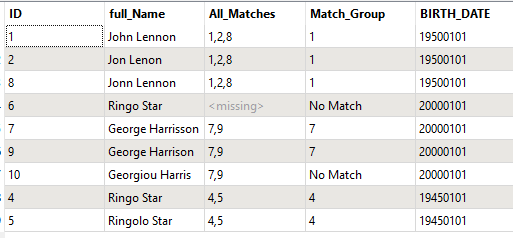
In this example, John Lennon and Jon Lenon are written almost the same way and they have the same BIRTH_DATE. We can consider it's the same person.
But John Lennon (1950-01-01) is not the same John Lennon (1985-01-01).
IDFIRST_NAMENAMEBIRTH_DATE1JohnLennon1950-01-012JonLenon1950-01-013JohnLennon1985-01-014RingoStar1945-01-015RingoloStar1945-01-016RingoStar2000-01-017GeorgeHarrisson2000-01-01
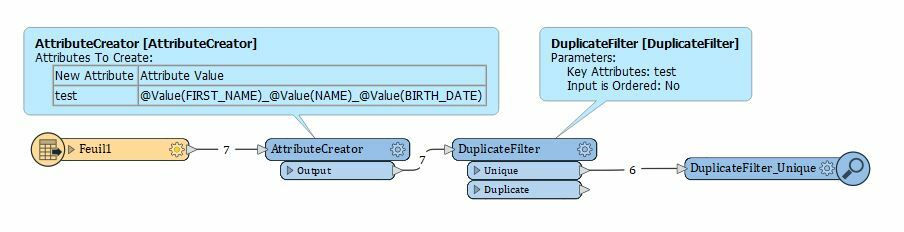
Would you have an idea how to do this kind of comparison? I tried the FuzzyDuplicateRemover but it doesn't give very good results and it doesn't store into a list the duplicated features potentially found (so I can't compare BIRTH_DATE).
Thanks!