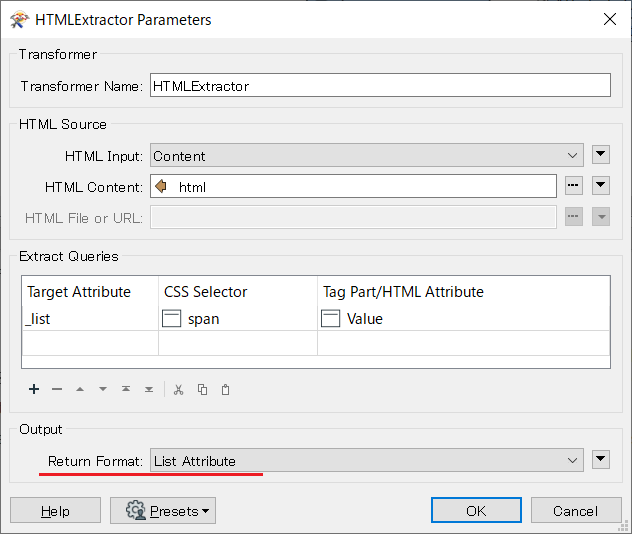
Hi, I am trying to extract a HTML page.
I would appreciate if any of the expert can explain to me on how to extract :
<tr data-group="Batu Pahat" data-group-2="Sekolah Agama Seri Chomel">
<td data-field="Daerah" class="ew-rpt-grp-field-1">
<span data-class="tpx1_1_Maklumat_Bencana_Daerah_Aktif_Banjir_Johor_PusatPemindahan">Sekolah Agama Seri Chomel</span></td>
<td data-field="Keluarga" class="ew-table-alt-row"><span>6</span></td>
I would like to extract the bolded ones from the HTML page using HTML Extractor
Your help will be kindly appreciated