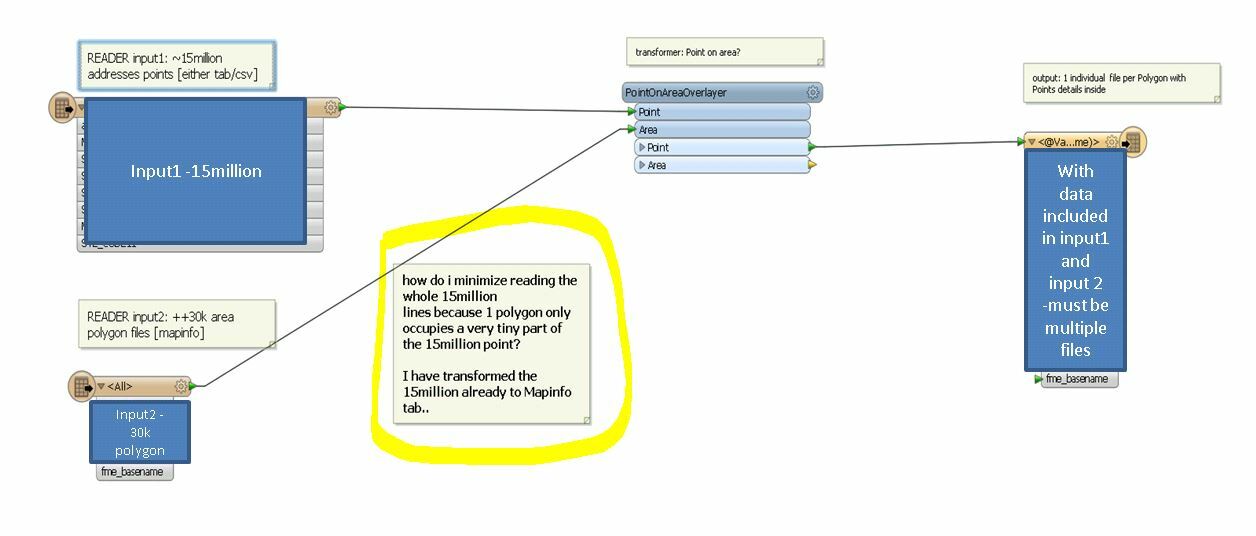
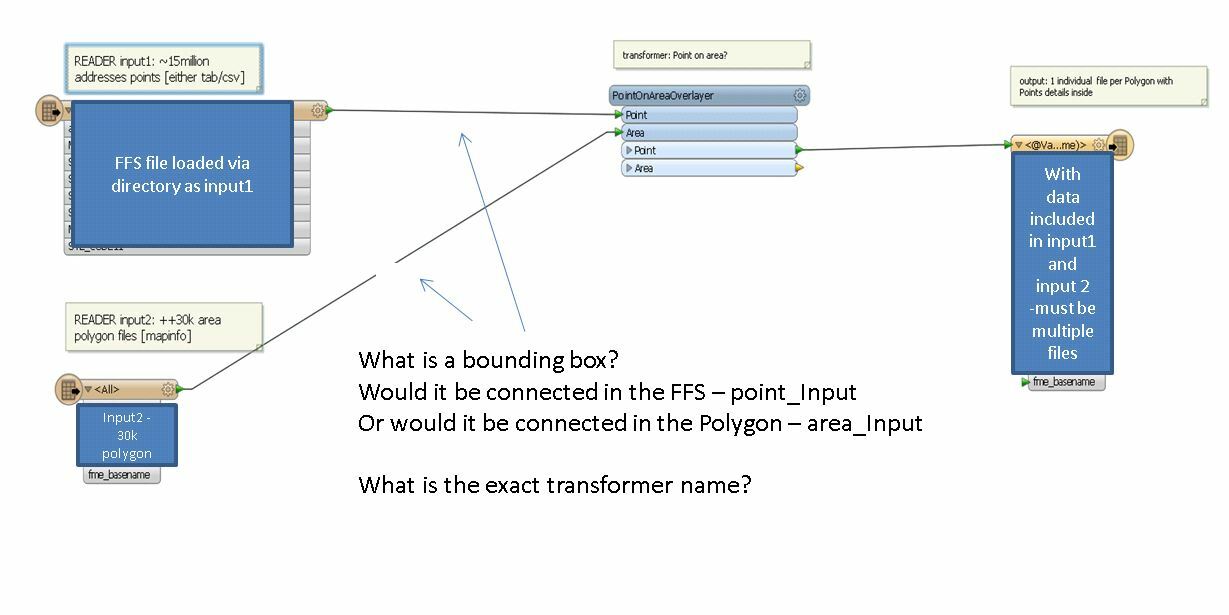
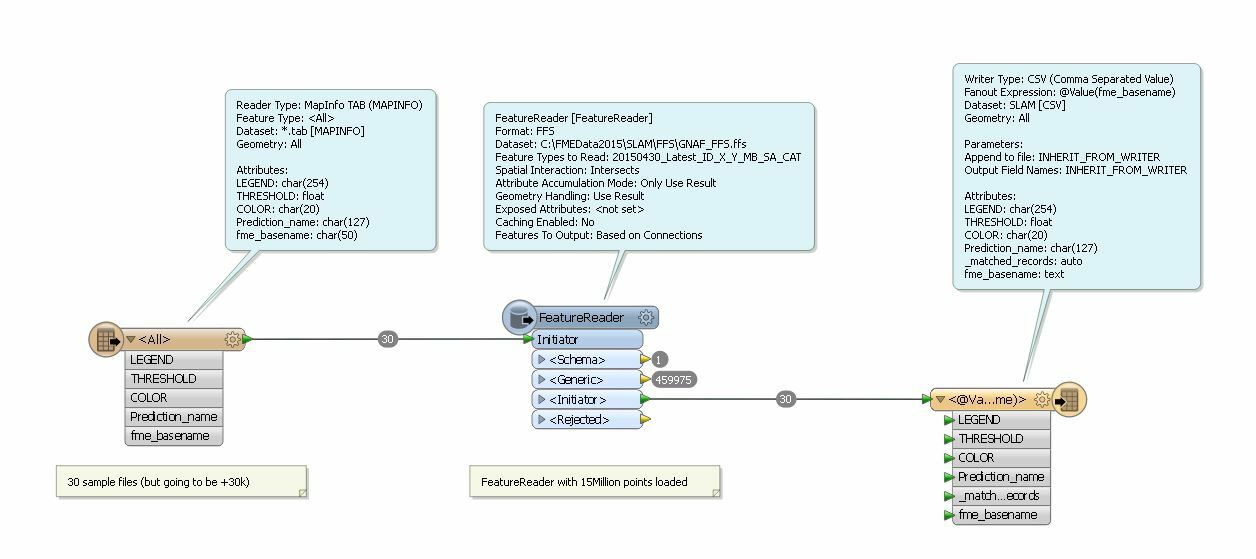
I have a massive amount of points within a country (++15Million) which represents addresses. [1massive csv file with lat/lon]
and I also have a huge amount of Polygons Area (++30k) which covers a number of area location. [multiple .tab files]
I need to get the number of points inside each polygon area
What would be the most optimised way to achieve this?
I am thinking of using a workspacerunner approach towards selecting 1-by-1 each polygon area mapping it out on the 15++million points however It would take a very long time to achieve this.
Is there a quick spatial approach on filtering to minimize the reading of the number of points, say it will only read within a certain area and not throught the 15million points?
thanks in advance
kind regards,
Jubert