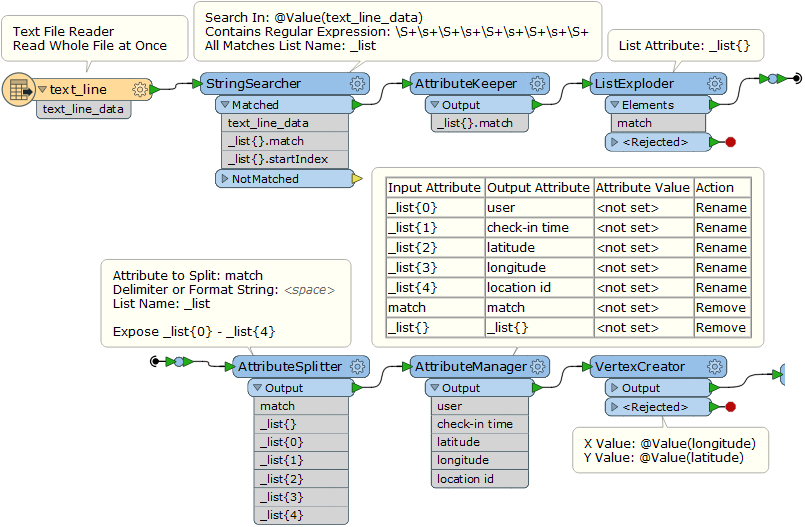
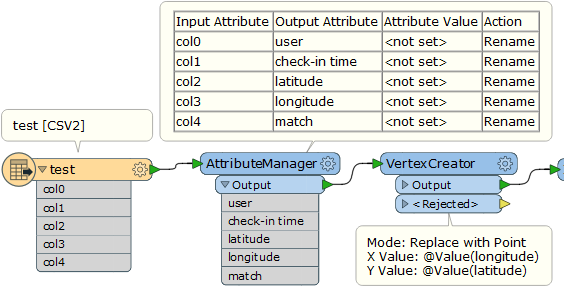
Hi all,
I have a check-in text data file with long/lat information, ,example as below:
[user] [check-in time] [latitude] [longitude] [location id]
196514 2010-07-24T13:45:06Z 53.3648119 -2.2723465833 145064
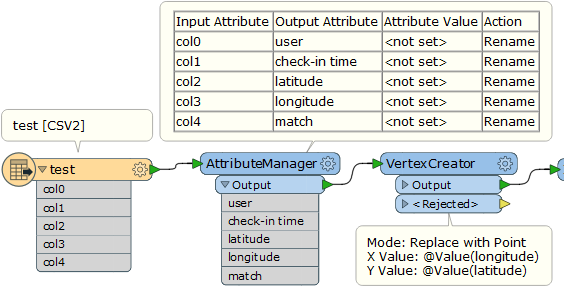
How can I convert it into point features? I tried several times but unsuccessful
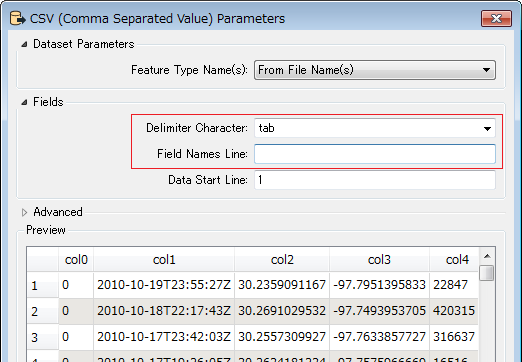
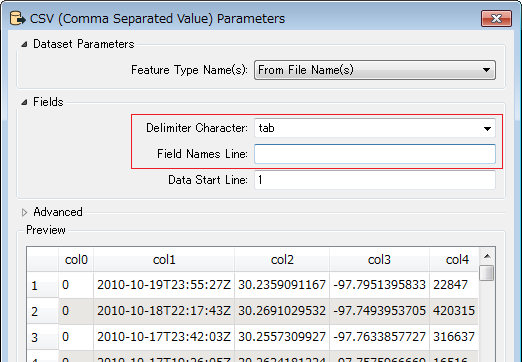
The data file looks like this:
0 2010-10-19T23:55:27Z 30.2359091167 -97.7951395833 22847 0 2010-10-18T22:17:43Z 30.2691029532 -97.7493953705 420315 0 2010-10-17T23:42:03Z 30.2557309927 -97.7633857727 316637 0 2010-10-17T19:26:05Z 30.2634181234 -97.7575966669 16516 0 2010-10-16T18:50:42Z 30.2742918584 -97.7405226231 5535878 0 2010-10-12T23:58:03Z 30.261599404 -97.7585805953 15372 0 2010-10-12T22:02:11Z 30.2679095833 -97.7493124167 21714 0 2010-10-12T19:44:40Z 30.2691029532 -97.7493953705 420315 0 2010-10-12T15:57:20Z 30.2811204101 -97.7452111244 153505 0 2010-10-12T15:19:03Z 30.2691029532 -97.7493953705 420315 0 2010-10-12T00:21:28Z 40.6438845363 -73.7828063965 23261 0 2010-10-11T20:21:20Z 40.74137425 -73.9881052167 16907 0 2010-10-11T20:20:42Z 40.741388197 -73.9894545078 12973 0 2010-10-11T00:06:30Z .....
Thanks for your help?