I'm having some problems with Clippers.
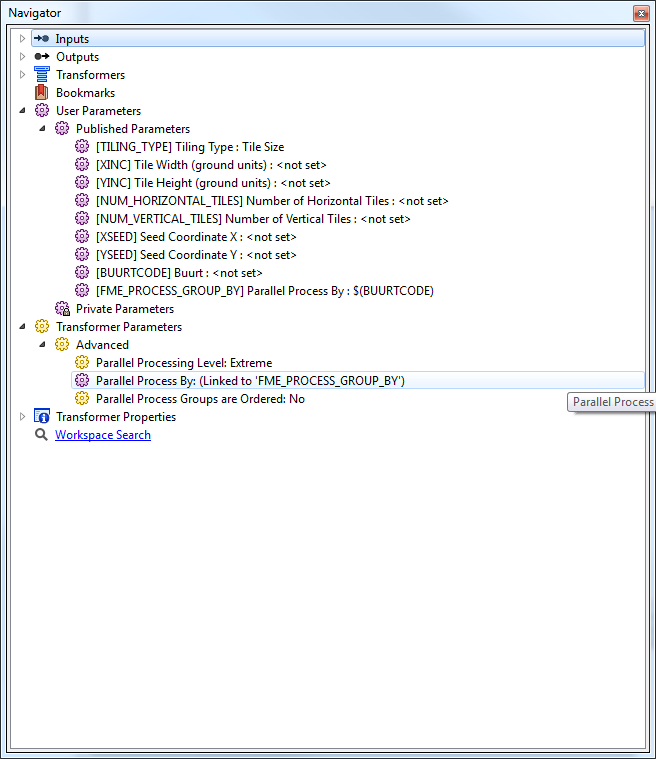
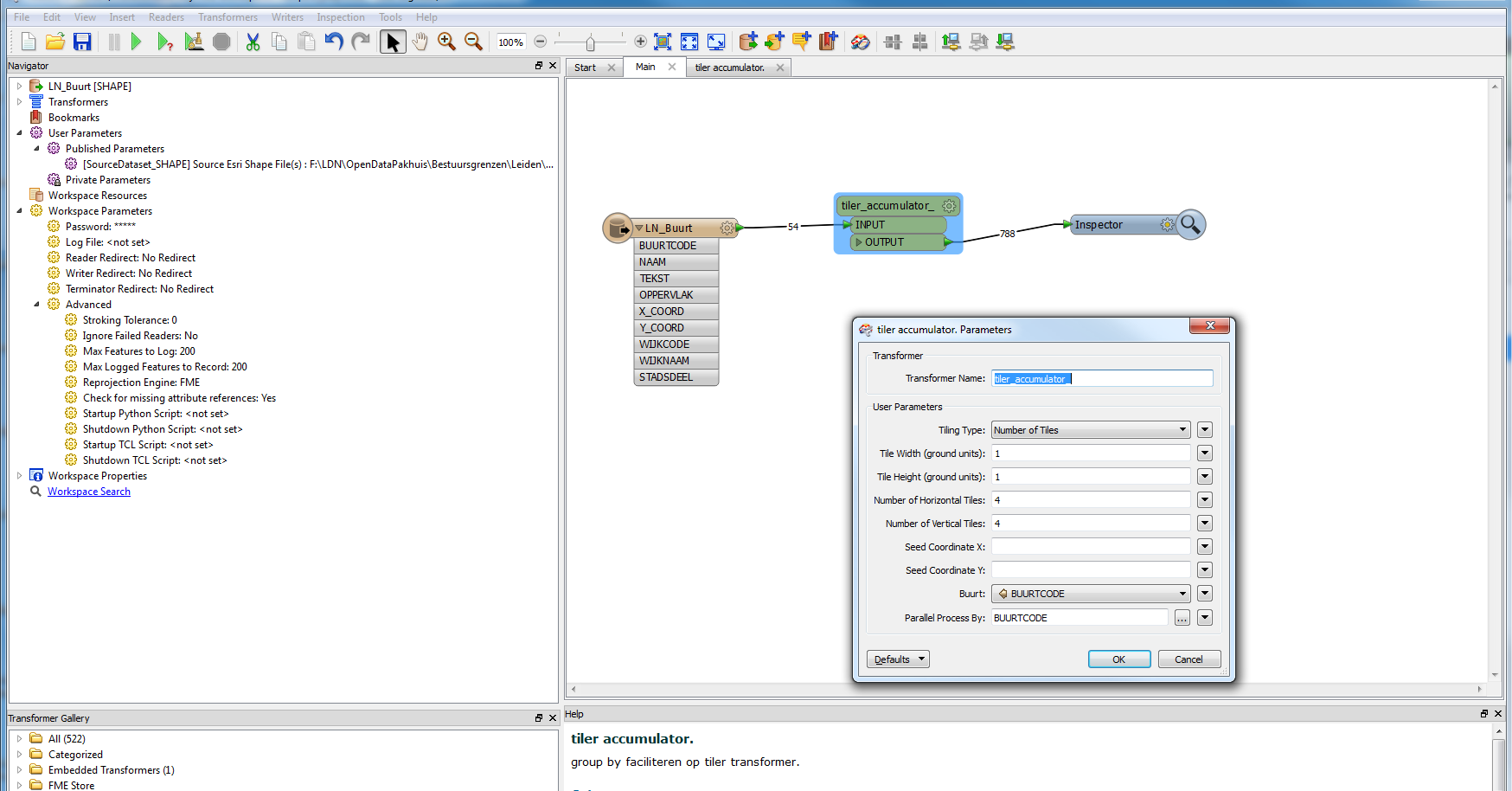
I have a set of features which I'm grouping together, and turning into a grid (BBoxAccumulator ->2D Gridder); I'm then using these features as Clippers against the original data (now clippees), using the same "grouping by".
Because the same dataset is both Clipper and Clippee, and the because Clippers have two blockers before they get to the Clipper as compared to none for the Clippee's, I'm struggling to optimise the Clipper (there's enough data that I end up running out of RAM and FME starts "optimising" data to disk).
I can't set "Clippers First", no matter what combination of featureHolder I put before the Clippees, they always get there first.
I've tried using a Sorter, and then "Clippers First" and/or "Input is ordered by group", but the process then goes even slower, and uses slightly more RAM because of the Sorter.
Any suggestions for how to optimise/do this?
Thanks,
Jonathan