
I have A csv file with more 10000000 records how can split into 5 smaller csv file (each with + o- 2000000 refcords) to performafter my actions ?



Userlevel 4
 +30
+30
- Evangelist
- 1873 replies
-
14 January 2018

Hi @frsisani,
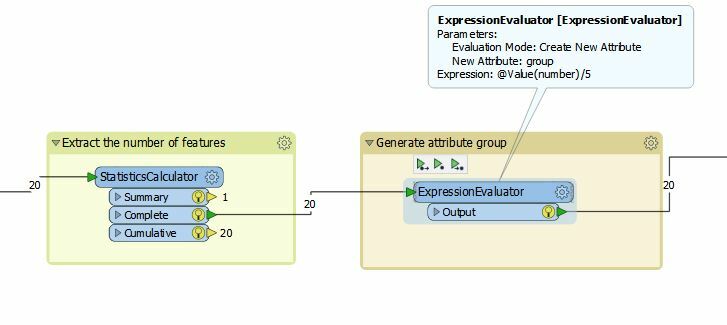
1 - After your Reader you can use the transformer StatisticsCalculator to have a count of features in Attribute = number.
2 - Use the transformer ExpressionEvaluator to calculate @Value(number)/5 and generate the attribute group.
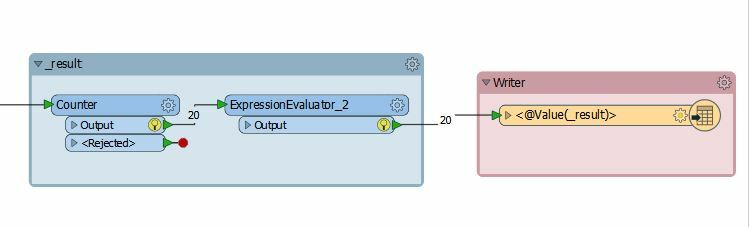
3 - Use the transformer Count to generate the attribute _count and after another transformer ExpressionEvaluator = result
int(@Value(number/@Value(group))
4 - Connect the output port ExpressionEvaluator in your Write file and set the configuration CSV File Name = _result
5 - Set in Navigator the Option Fanout.
Attached the Workspace. - workspace-fanout-split.fmw
Thanks,
Danilo

Userlevel 4
+25
- Safer
- 2392 replies
-
15 January 2018

Alternatively a Counter/AttributeRangeFilter combination might be useful.
I also note a Grouper transformer on the FME Hub, although I haven't tried it myself.


 +22
+22
- Contributor
- 1959 replies
-
15 January 2018

If the order of the records is irrelevant, I would use a ModuloCounter (set to 5), and fanout based on the _modulo_count. That way the features aren't being kept in memory to determine the total number of features (StatisticsCalculator).


Userlevel 4
- 8167 replies
-
16 January 2018

Hi @frsisani,
1 - After your Reader you can use the transformer StatisticsCalculator to have a count of features in Attribute = number.
2 - Use the transformer ExpressionEvaluator to calculate @Value(number)/5 and generate the attribute group.
3 - Use the transformer Count to generate the attribute _count and after another transformer ExpressionEvaluator = result
int(@Value(number/@Value(group))
4 - Connect the output port ExpressionEvaluator in your Write file and set the configuration CSV File Name = _result
5 - Set in Navigator the Option Fanout.
Attached the Workspace. - workspace-fanout-split.fmw
Thanks,
Danilo
Userlevel 4
- 8167 replies
-
16 January 2018
Alternatively a Counter/AttributeRangeFilter combination might be useful.
I also note a Grouper transformer on the FME Hub, although I haven't tried it myself.

Userlevel 2
 +17
+17
- Contributor
- 7538 replies
-
16 January 2018

I would just use a feature type fanout expression like this.
output_@Evaluate(@int(@Count()/2000000))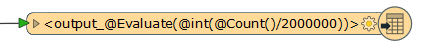
Userlevel 4
+25
- Safer
- 2392 replies
-
16 January 2018
If the order of the records is irrelevant, I would use a ModuloCounter (set to 5), and fanout based on the _modulo_count. That way the features aren't being kept in memory to determine the total number of features (StatisticsCalculator).
+22
- Contributor
- 1959 replies
-
16 January 2018
I would just use a feature type fanout expression like this.
output_@Evaluate(@int(@Count()/2000000))
Userlevel 2
+17
- Contributor
- 7538 replies
-
16 January 2018
I would just use a feature type fanout expression like this.
output_@Evaluate(@int(@Count()/2000000))

Reply
Enter your username or e-mail address. We'll send you an e-mail with instructions to reset your password.