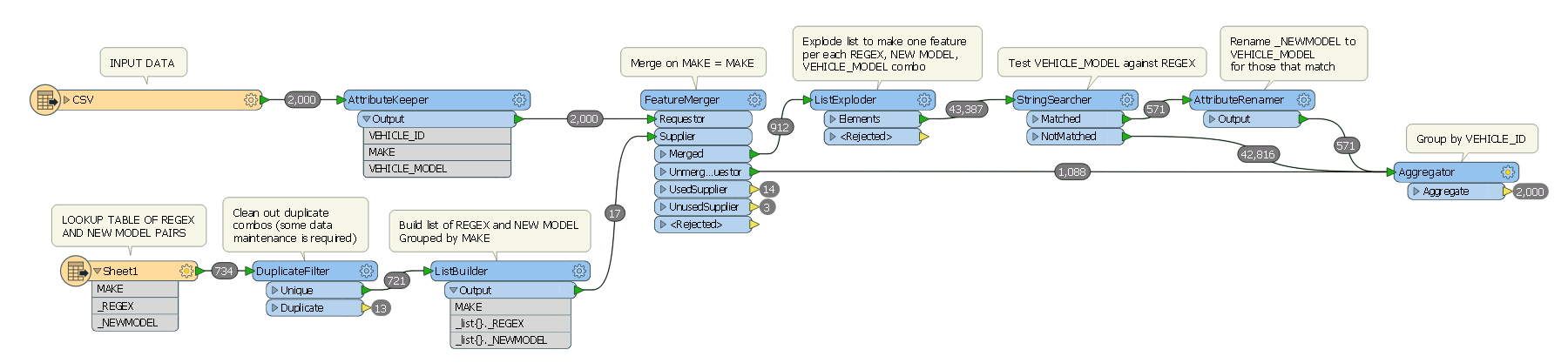
Hi,
I have a series of regular expression and new string pairs.
If the regular expression gets a match I don't just want to replace the characters that match I want to replace the whole matched string with the new string.
As an example;
If the old string is - CAROLA 1.6ABC
The regex is - C[AO]?[CR]R?O?O?L?L?L?LI?A?
The new string needs to be - COROLLA
To make matters more difficult, there are about 400+ unique pairings.
Thanks in advance