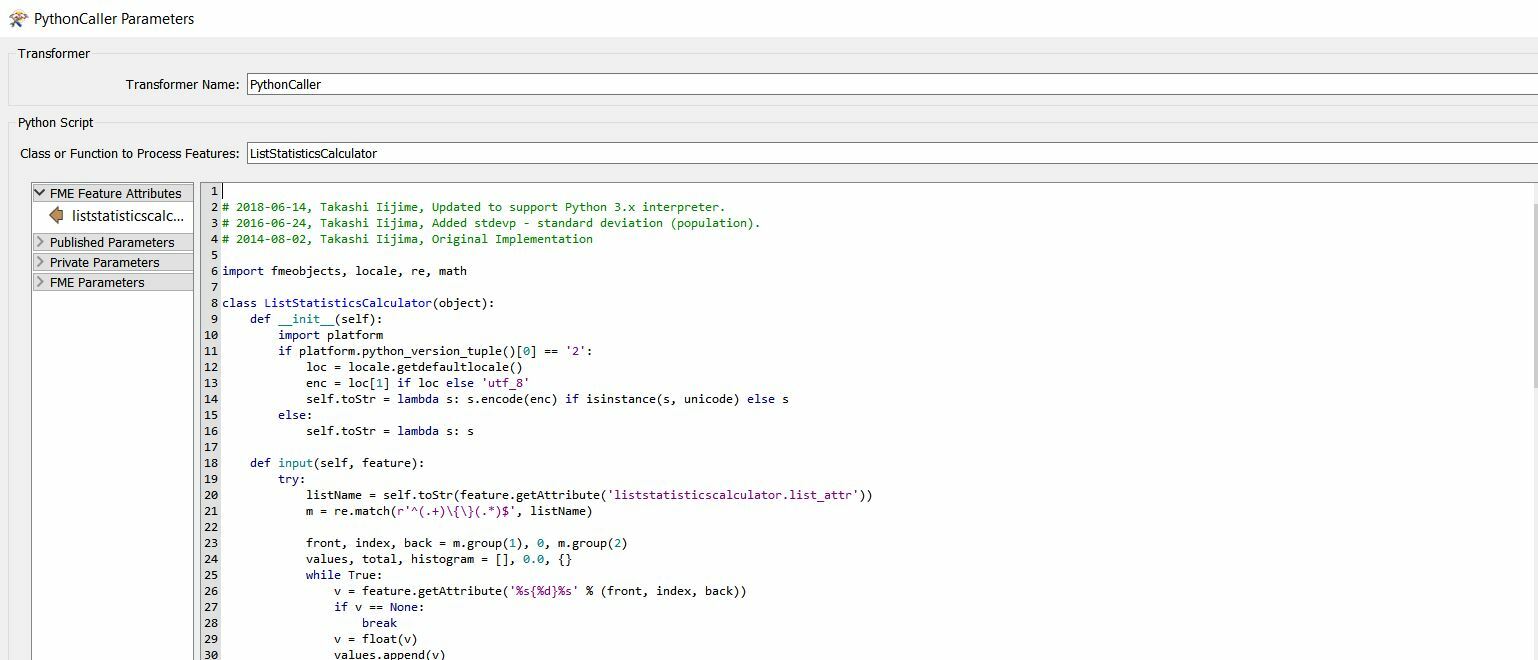
Hello,
I would like to read all attributes for some specific fields and then compute some satistics.
I know that it is possible with multiple statistics calculators and feature mergers.
How can I do this inside a python caller?
Thanks
Best answer by takashi
View original