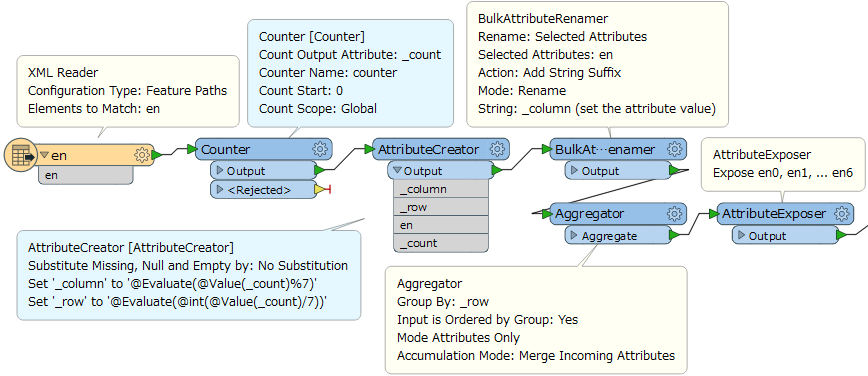
Hi, I have a xml that unfortunately isn't very structured for me to extract attributes easily. Every <en> line contains attributes that I want to put into specific columns in a structured table.
For example:
<en>3121 </en>
<en> Colorado City </en>
<en> 50.852010 </en>
<en> -89.672167</en>
<en> 5755 0555 </en>
<en> Map 593 N10 Arizona Country Directory </en>
<en> Office </en>
<en>3020 </en>
<en> Toronto </en>
<en> 50.578010 </en>
<en>-88.887679 </en>
<en> 5875 1234 </en>
<en> Map 105 K6 Ontario Country Directory </en>
<en> Agency </en>
and so on...
I have 2588 rows of this and there is a pattern. Is there a way for me to extract out every nth row be put together into one column? In this example, every 7th row should be in one column so I would have a field for post code, name, latitude, longitude and so on? Thank you.
Best answer by takashi
View original