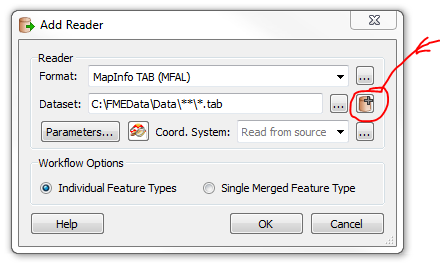
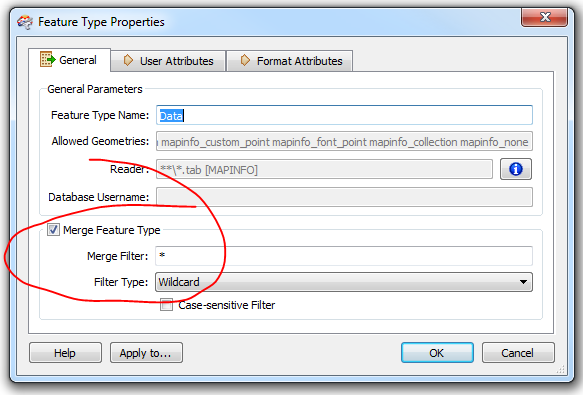
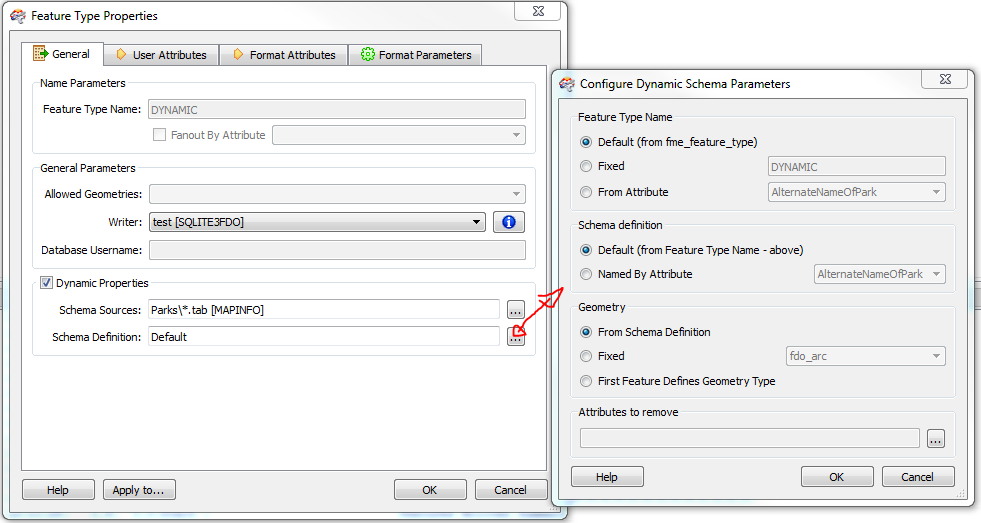
Im just curious to know what might be the best way to deal with multiple MapInfo TAB files output to an ArcSDE geodatabase.
Is it the most efficient way to bring all features into the workspace and have them directed to the writer, or is there a way of looping through the location folder, processing each one until completion? (sounds tricky - is it doable?)
Ive typically dragged all feature classes into one or many workspaces and processed accordingly.
Appreciate your response(s) in advance.
Sean