Hi,
I would to use FME elements to parse HTML file.
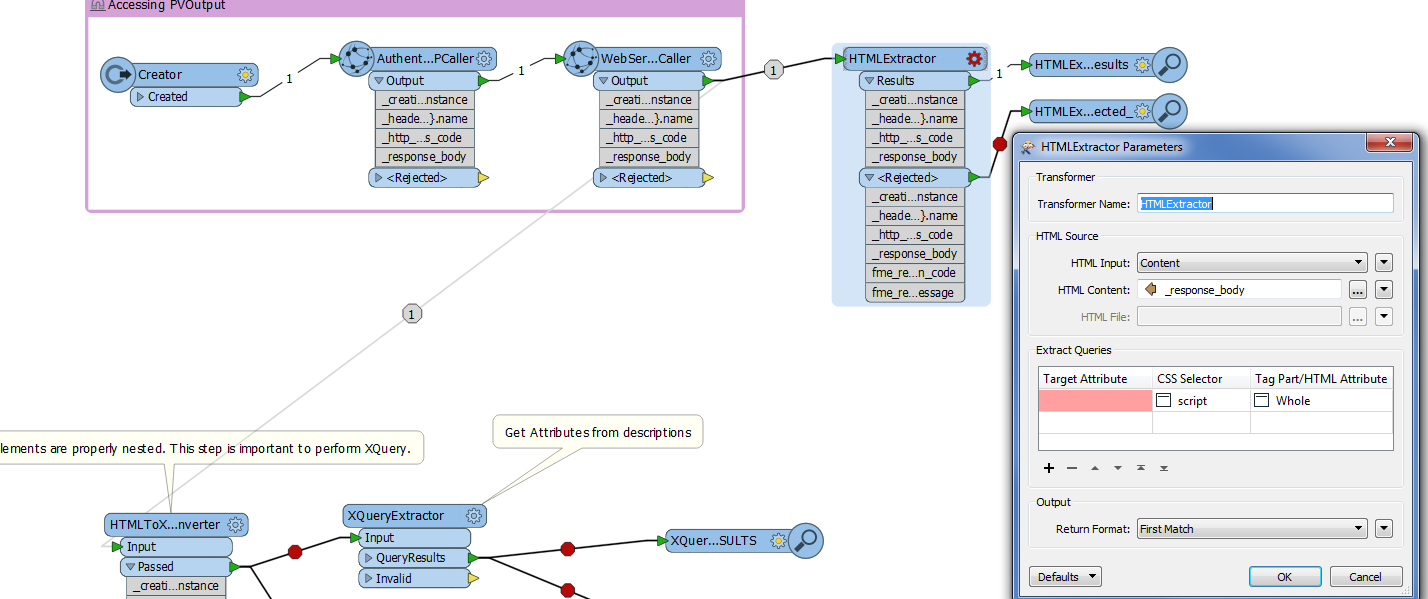
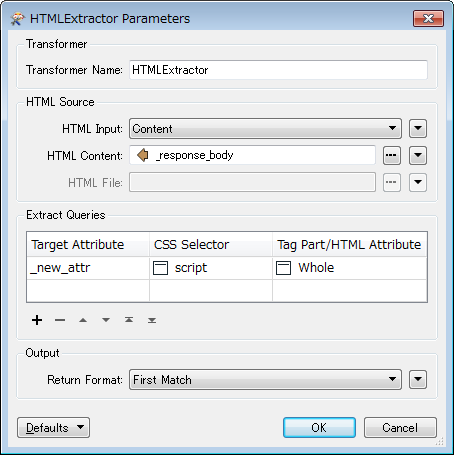
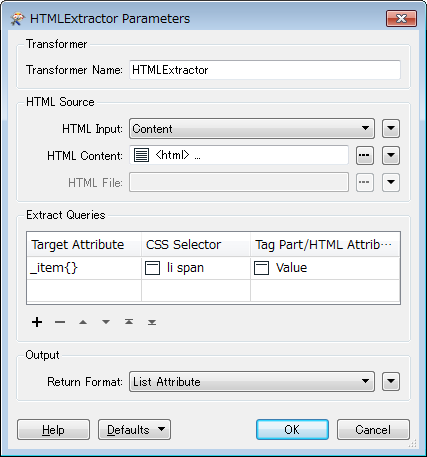
I have the following scenario. Navigating through various html pages, parse the html content of these pages, and then store the returned data in a specific format for further processing.
I have used HTTPCalled for calling the webpage and retrieved the html content in the 'response_body' field. I have tried to connect 'response_body' to HTMLToXMLConverter but unfortunately it didn't work.
So I wonder if there's a way to parse html content of webpages?
Thanks for your help!