Dear community,
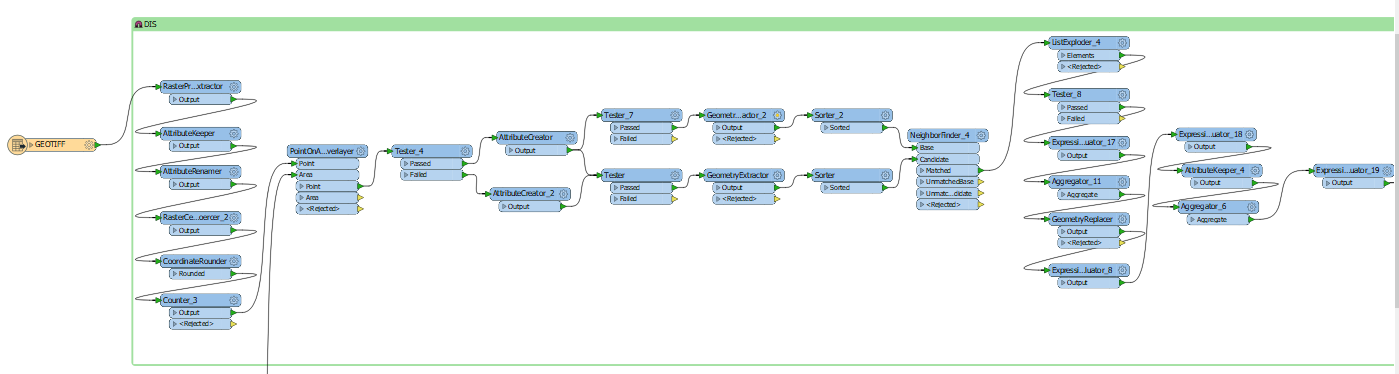
I need to calculate the weighted distance from many points to all the others within a radius of 2000m. For this task I combined the NeigborFinder with a ListExploder and a ExpressionEvaluator to calculate the weighted distance per point.
Now, the ListExploder produces a huge amount of elements which causes memory issues, although I'm using a 64-Bit machine with 65 GByte of RAM. Is there another way of solving this task e.g. without ListExploder? I think I need the ListExploder to be able to calculate the weighted distance for every point in the ExpressionEvaluator...
Thank you for your help,
Vincent