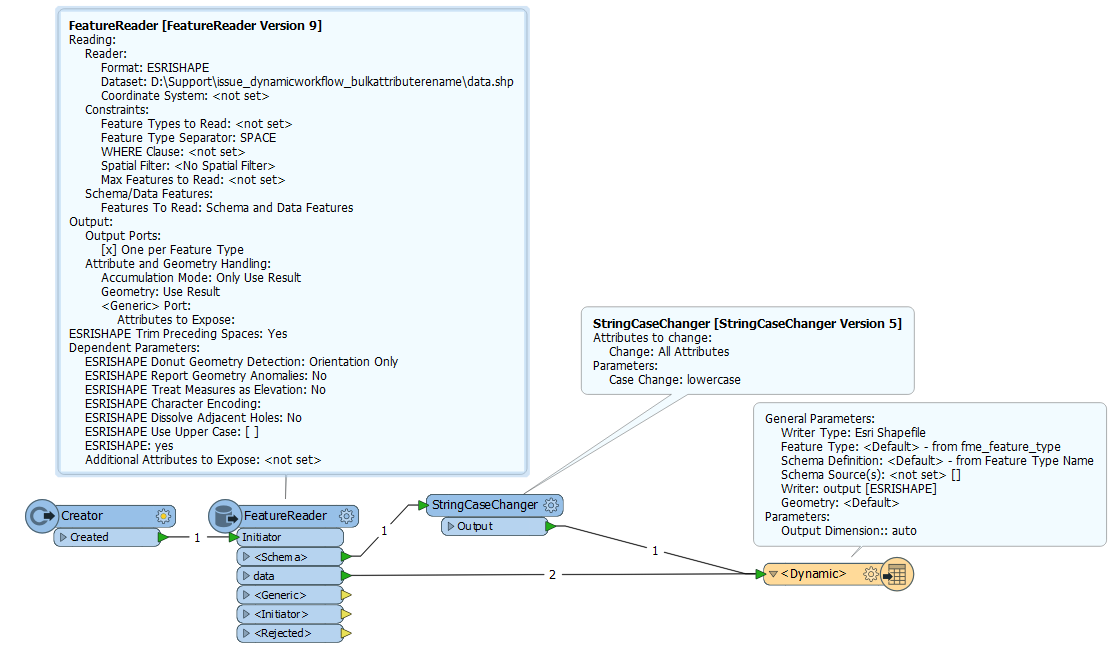
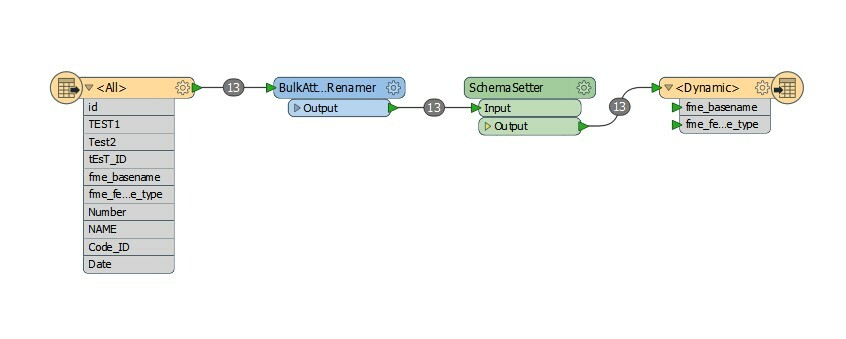
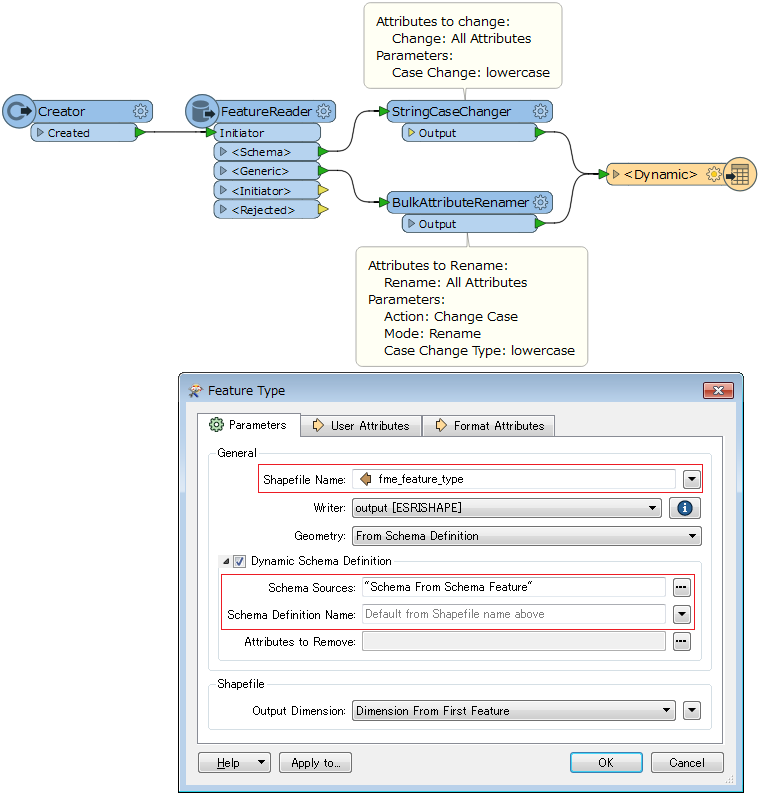
FME Desktop 2017.1 build17725
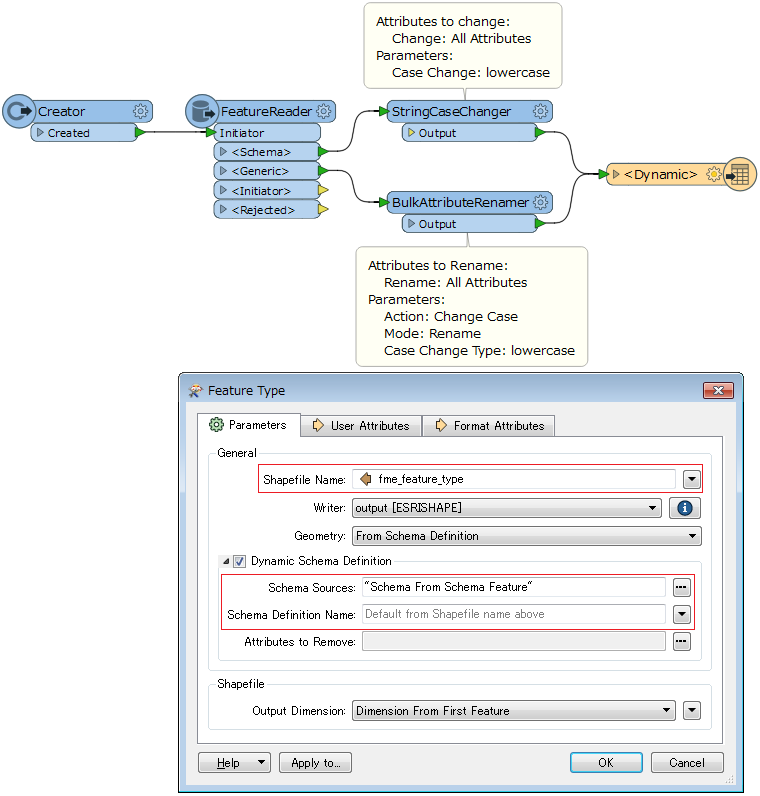
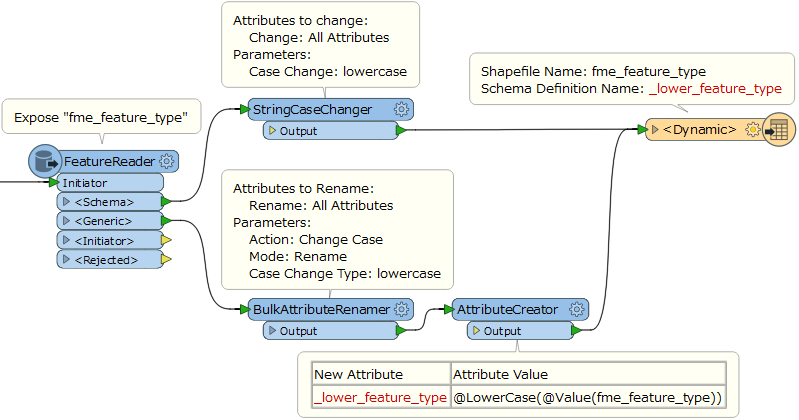
When I create a simple Dynamic Workflow from shape to shape, everything works fine.
When I put the BulkAttributeRenamer to the Workspace, the results are weird.
I like to have all attribute names lowercase.
Instead, attribute names remain capital, but all my data is lost in the output...
Is that a known issue?
Best answer by redgeographics
View original