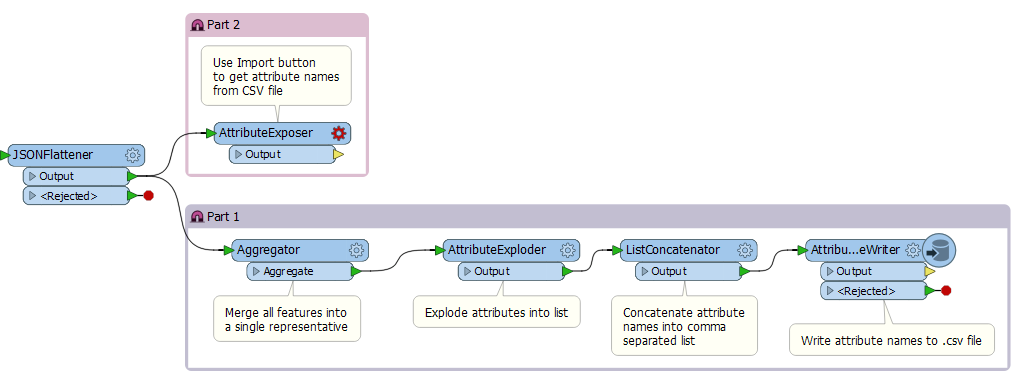
Both the XMLFlattener and JSONFlattener (and the Flatten options in the XMLFragmenter and JSONFragmenter) give you the option to expose the newly created attribute names to the workspace.
However, if there are a lot attributes, it can be a pain to type them all in. As well, any changes to the input XML or JSON may result in new attributes to expose.