Hi,
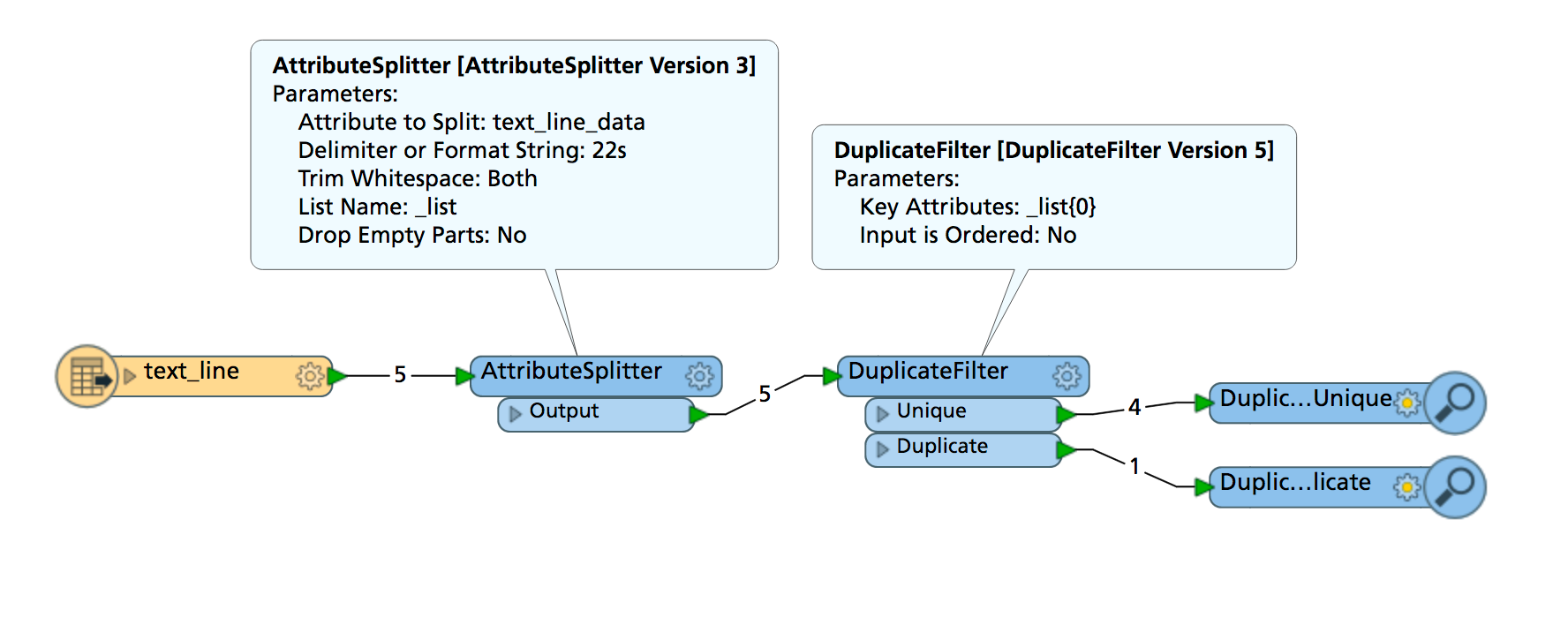
I have a fixed width text file and would like to remove some of the rows where a certain portion of the row is duplicated, for example please see extract below:
NE500086033 15.10.201831.12.2099Masterson
NE500085977 08.10.201831.12.2099Gilmore
NE500085699 24.09.201831.12.2021Doherty
NE500085699 24.09.201831.12.2099Banks
NE500085312 10.09.201831.12.2099Moyo
If the parts in bold are the same I would like to remove both records from the file. Then output the file in exactly the same format with the duplicates removed. I am using the CAT reader to read the file but I'm not 100% sure which is the best writer to use. Any advice is much appreciated.
Thanks,
Charlie