Hello,
I am curious of there is a setting or ability to ignore "insert errors" related to primary key constraints in a SQL Database. The workspace writer is doings its job by not allowing duplicate keys to be created but I would like to override/ignore these errors to allow the workspace to continue and finish successfully.
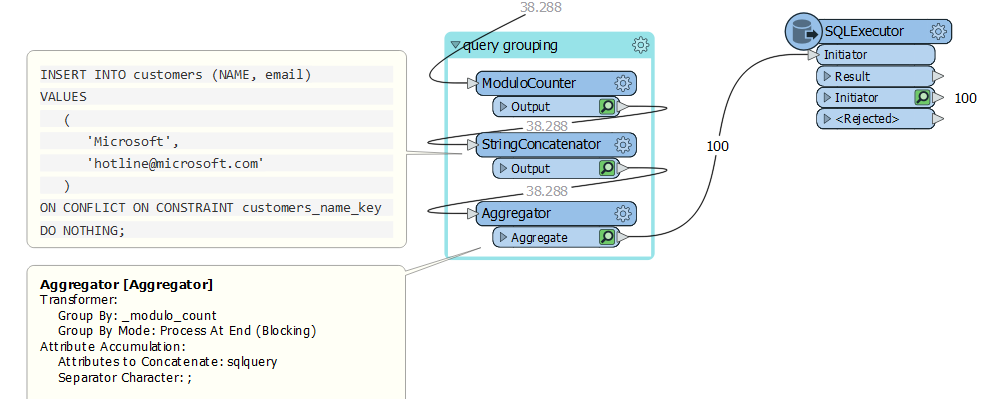
I know I could use an UpdateDetector or reader from the destination to prevent these inserts from hitting the writer but this will really slow down the process to read all existing records to perform this compare.
I was hoping to set a SQL writer or workspace property to allow the workspace to continue when a duplicate key is encoutered.
Any tips or techniques for this situation without actually reading the destination and comparing the input records?
Thanks
Ronnie
Best answer by courtney_m
View original