Hi all,
I'm new to FME and am trying to deal with a datset that has duplicates in. However each duplicate contains some information that I need to preserve into new columns.
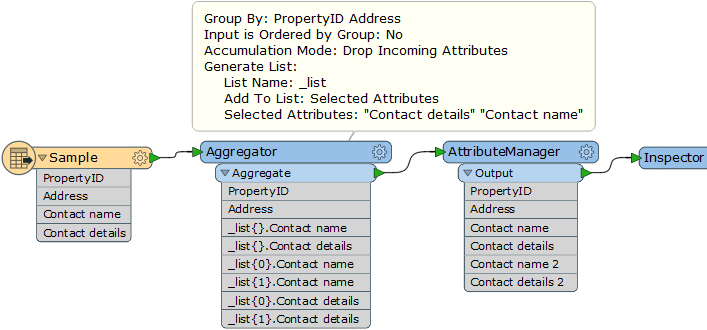
A simplified version is something like this:
PropertyIDAddressContact nameContact details00011 High StreetMr Smith0121232800000011 High StreetMr Jones0121232800100022 Low StreetMr Birmingham0121232800200022 Low StreetMr Warwick01212328003
And what I need to end up with is more like this:
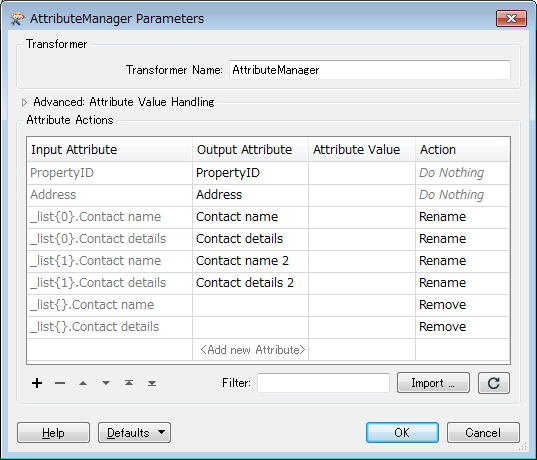
PropertyIDAddressContact nameContact detailsContact name 2Contact details 200011 High StreetMr Smith01212328000Mr Jones0121232800100022 Low StreetMr Birmingham01212328002Mr Warwick01212328003
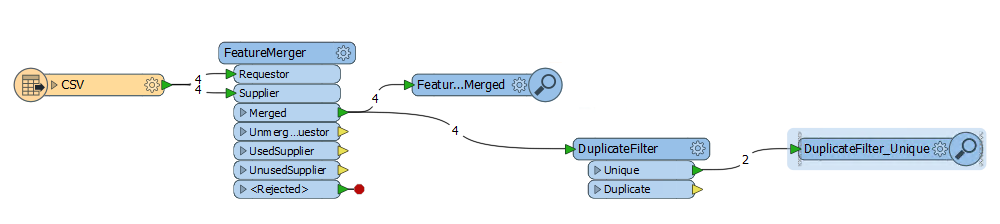
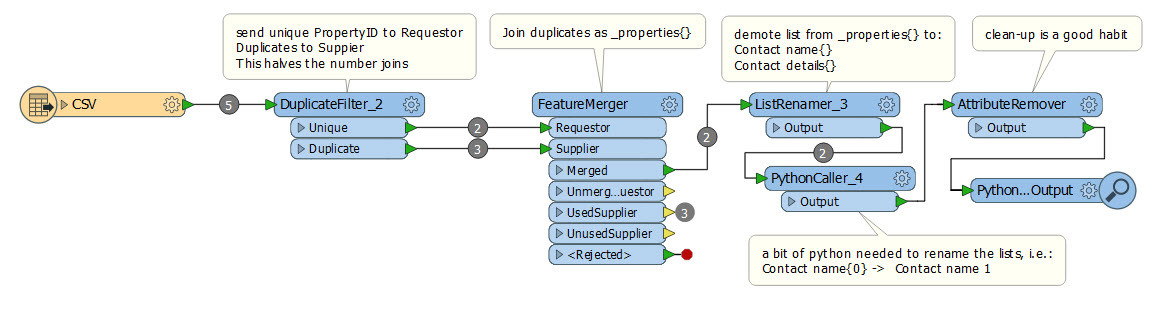
It's been suggested to me to use FeatureMerger after multiple DuplicateFilters, but I can't figure out how to bring each set of filtered duplicates back in to a single dataset whilst preserving the data out of the duplicate entries.
Any help, pointers or example workspaces would be greatly appreciated.
Cheers, Mark
Best answer by fmelizard
View original